Redis面试题
缓存设计
- 什么是缓存穿透,怎么解决?
- 布隆过滤器是如何实现的?
- 什么是缓存击穿,怎么解决?
- 什么是缓存雪崩,怎么解决?
- Redis 双写一致问题如何解决?
- Redis 分布式锁如何实现?
- 分布式锁如何合理的控制锁的有效时长?
高可用
- Redis 集群有哪些方案, 知道嘛?
- 什么是 Redis 主从同步,数据是怎么同步的?
- 你们使用 Redis 是单点还是集群 ?
- Redis 分片集群中数据是怎么存储和读取的?
- Redis 分片集群如何实现扩容和缩容?
- Redis 集群脑裂是如何导致的,如何解决?
- 怎么保证 Redis 的高并发高可用?
- 你们用过 Redis 的事务吗 ? 事务的命令有哪些?
Redis 原理
- Redis 的数据过期策略有哪些?
- Redis 的数据淘汰策略有哪些?
- Redis 是单线程的,但是为什么还那么快?
📌提示:我看你做的项目中都用到了Redis,你在最近的项目中哪些场景使用了Redis呢?
我们需要结合项目经验,验证我们的项目场景真实性,二是为了作为深入发问的切入点
- 缓存:缓存三兄弟(穿透,击穿,雪崩)、双写一致、持久化、
- 分布式锁
- 消息队列、延迟队列
- 数据过期策略、数据淘汰策略
缓存设计
📌思考:缓存三兄弟
穿透无中生有Key,布隆过滤空隔离。
缓存击穿过期Key,锁与非期解难题。
雪崩大量过期Key,过期时间要随机。
面试必考三兄弟,可用限流来保底。
缓存穿透
缓存穿透:查询一个不存在的数据,MySQL 查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库。
解决方案一:缓存空数据,查询返回的数据为空,仍然把这个空结果进行缓存。
举例:一个 Get 请求:api/news/getById/1
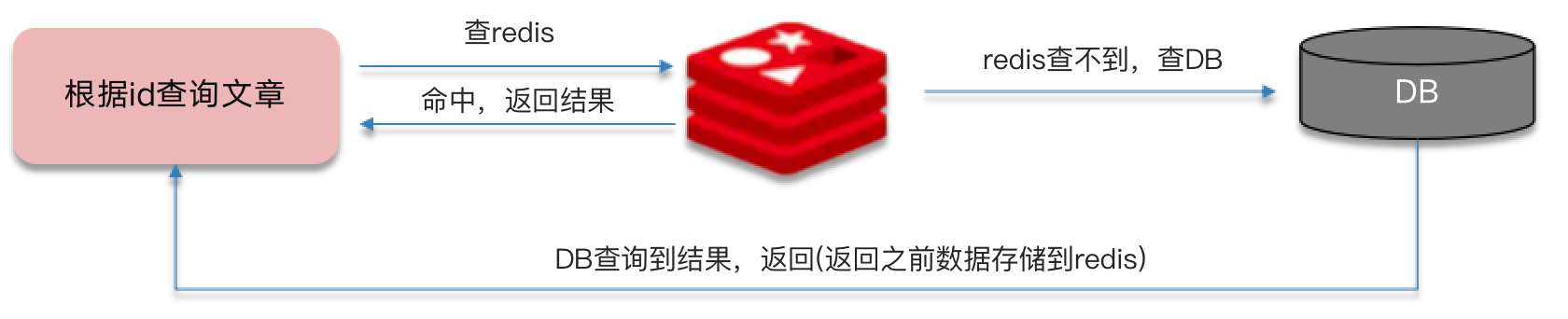
- 优点:简单
- 缺点:消耗内存,可能会发生不一致的问题。
解决方案二:布隆过滤器

- 优点:内存占用少,没有多余Key
- 缺点:实现复杂,存在误判
布隆过滤器
bitmap(位图):相当于是一个 bit 位为单位的数组,数组中每个单元只能存储二进制数0或1
布隆过滤器作用:用于检索一个元素是否在一个集合中。

实现误判的情况

误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗。
具体实现
@Slf4j
public class BloomFilter {
/**
* 测试误判率
*
* @param bloomFilter
* @param size
* @return
*/
public static int getData(RBloomFilter<String> bloomFilter, int size) {
// 记录误判的条数
int count = 0;
for (int x = size; x < size * 2; x++) {
if (bloomFilter.contains("add" + x)) {
count++;
}
}
return count;
}
/**
* 初始化布隆过滤器
*
* @param bloomFilter
* @param size
*/
public static void initData(RBloomFilter<String> bloomFilter, int size) {
// 第一个参数:布隆过滤器存储的元素个数,第二个
bloomFilter.tryInit(size, 0.05);
// 在布隆过滤器初始化数据
for (int x = 0; x < size; x++) {
bloomFilter.add("add" + x);
}
log.debug("初始化完成");
}
}💡思考:什么是缓存穿透 ? 怎么解决 ?
缓存穿透指的是查询一个不存在的数据,从缓存查不到该数据,导致每次请求都会到数据库查询。请求太多会导致数据库挂掉,一般这种情况是遭到了攻击。可以采用缓存空数据和布隆过滤器两种方案解决。
💡思考:布隆过滤器是如何实现的?
布隆过滤器可以通过 Redisson 实现,底层先去初始化一个比较大的数组,里面存放0,在 Key 经过三次hash后,模于数组长度然后找到数据下标的数据,从0改成1,主要三个数组的位置就可以标记一个Key的存在。查找过程也是相同的。
布隆过滤器会有一定的误判,我们一般设置误判率为5%,低于5%需要增加数组长度,也会带来更多的内存消耗。
💡思考:两种方案有什么优缺点?
- 缓存空数据很简单,但是会造成内存浪费,有时还会导致数据不一致。
- 布隆过滤器内存占用少,没有多余的Key,但是会存在一定的误判。
缓存击穿
缓存击穿:给某一个 Key 设置了过期时间,当 Key 过期的时候,恰好这时间点对这个 Key 有大量的并发请求过来,这些并发的请求可能会瞬间把 DB 压垮。

有两种解决方案
- 互斥锁
- 逻辑过期
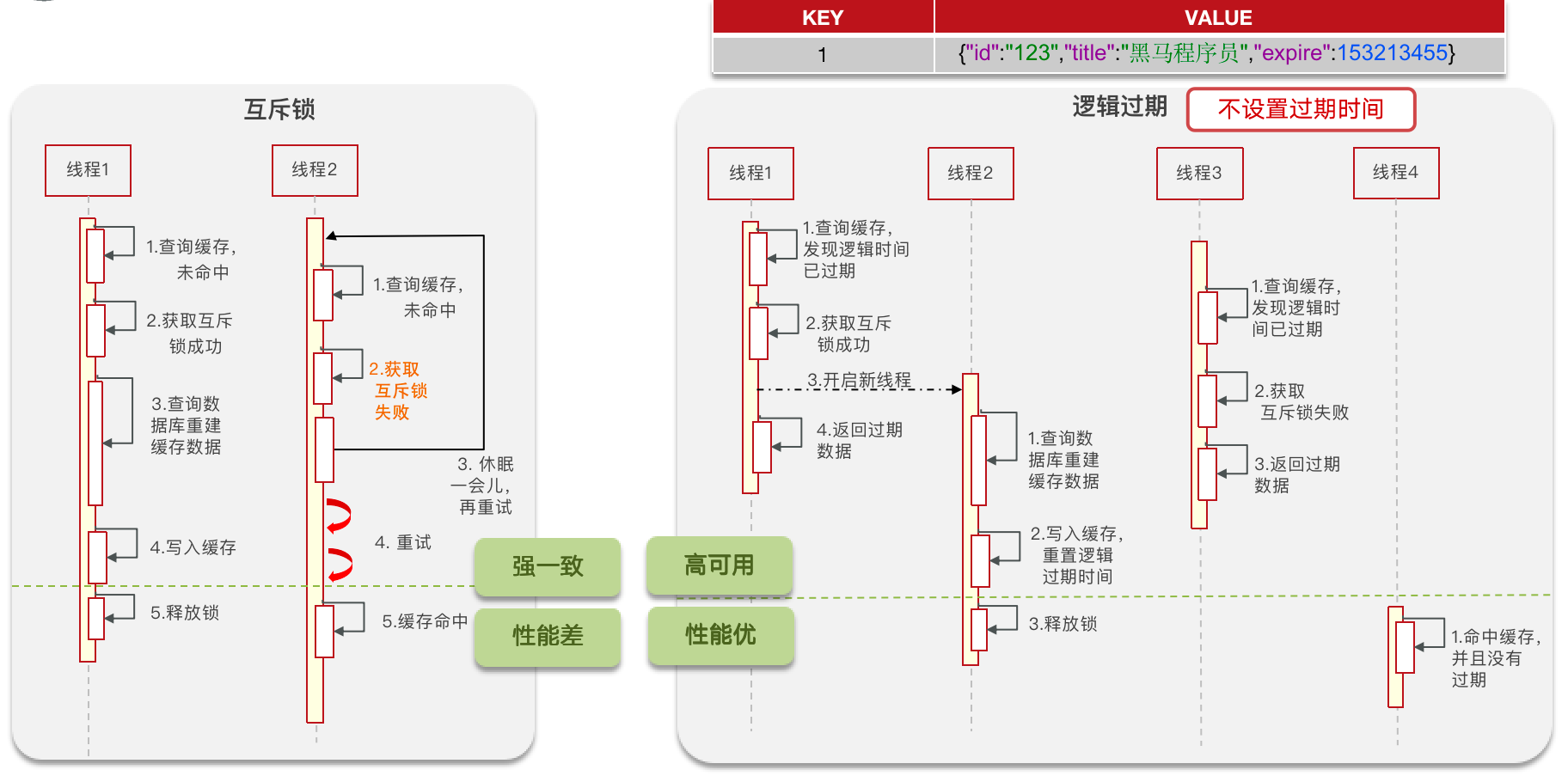
💡思考:什么是缓存穿透,怎么解决
缓存击穿是指设置了过期时间的 Key,在过期的时候,这个 Key 有大量的并发请求过来。这时候所有的查询都从数据库查询导致把数据库压垮。
有两种方案来解决:
- 互斥锁在缓存失效的时候设置一个互斥锁,互斥锁设置成功后再进行数据库查询操作在设置缓存,否则就重新尝试获取缓存。
- 逻辑过期则是在设置 Key 的时候不给过期时间,而是设置过期时间字段,在查询到数据的时候获取到过期时间判断是否过期,如果过期则重新开一个线程对数据进行同步,当前线程返回当前数据,虽然数据不是最新的。
两种方法各有利弊,互斥锁是保证强一致但是性能不高,在缓存重建的过程中是无法对数据进行查询的。逻辑过期保证了高可用性,性能比较高,保证了数据最终一致性,但是没有保证数据实时一致性。
缓存雪崩
缓存雪崩是指在同一时间段大量的缓存 Key 同时失效或者 Redis 服务宕机,导致大量请求到达数据库,带来巨大压力。

解决方案:
- 给不同的Key的TTL添加随机值。
- 利用Redis集群提高服务的可用性:哨兵模式、集群模式
- 给缓存业务添加降级限流策略:Nginx 或者 Spring Cloud Gateway
- 降级可以作为系统的保底策略,适用于穿透、击穿、雪崩
- 给业务添加多级缓存:Guava 或 Caffeine
💡思考:什么是缓存雪崩 ? 怎么解决 ?
缓存雪崩是指大量 Key 同一时间失效或者 Redis 服务宕机,导致大量请求到达数据库,给数据库带来巨大压力。
- 给不同的 Key 的 TTL 添加随机值。
- 利用 Redis 集群提高服务的可用性:哨兵模式、集群模式
- 给业务添加多级缓存
- 给缓存业务添加降级限流策略,降级可以作为系统的保底策略,适用于穿透、击穿、雪崩
双写一致
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
- 读操作:缓存命中,直接返回;缓存未命中,查询数据库,写入缓存,设定超时时间。
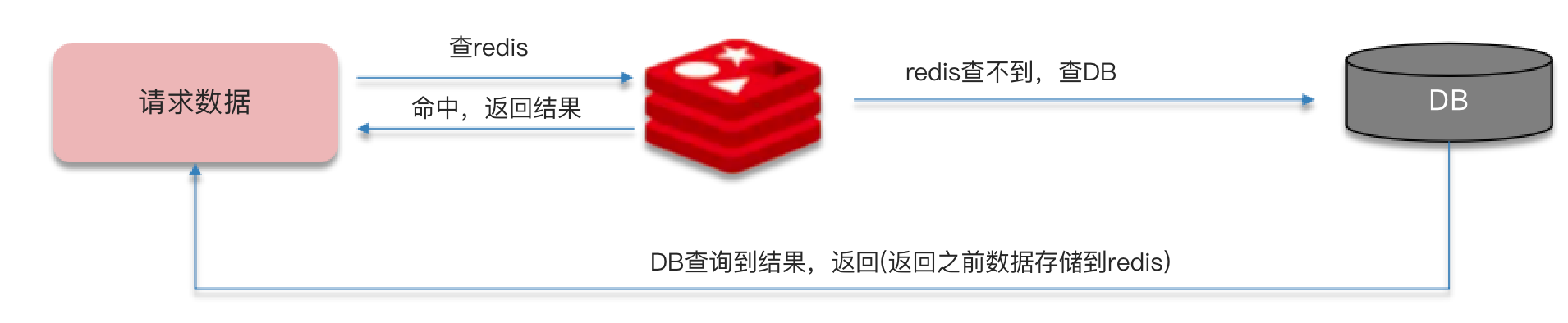
- 写操作:延迟双删和互斥锁
延迟双删的问题
- 先删除缓存还是先修改数据?
- 为什么要删除两次缓存?
- 为什么要延迟双删?
先删除缓存还是先修改数据库:都有可能导致脏数据。
- 先删除缓存在操作数据库:线程一删除缓存,在没有更新数据库之前线程二将数据库中的数据写入缓存。
- 先操作数据库在删除缓存:线程一未命中缓存,这时线程二在更新数据库并进行缓存删除,线程一将没修改之前的数据写入缓存。

- 为什么要删除两次缓存:降低出现脏数据的风险。
- 为什么要延迟双删:主从模式同步数据会有延迟,但是延迟的时间不好控制,都会有出现脏数据的风险。

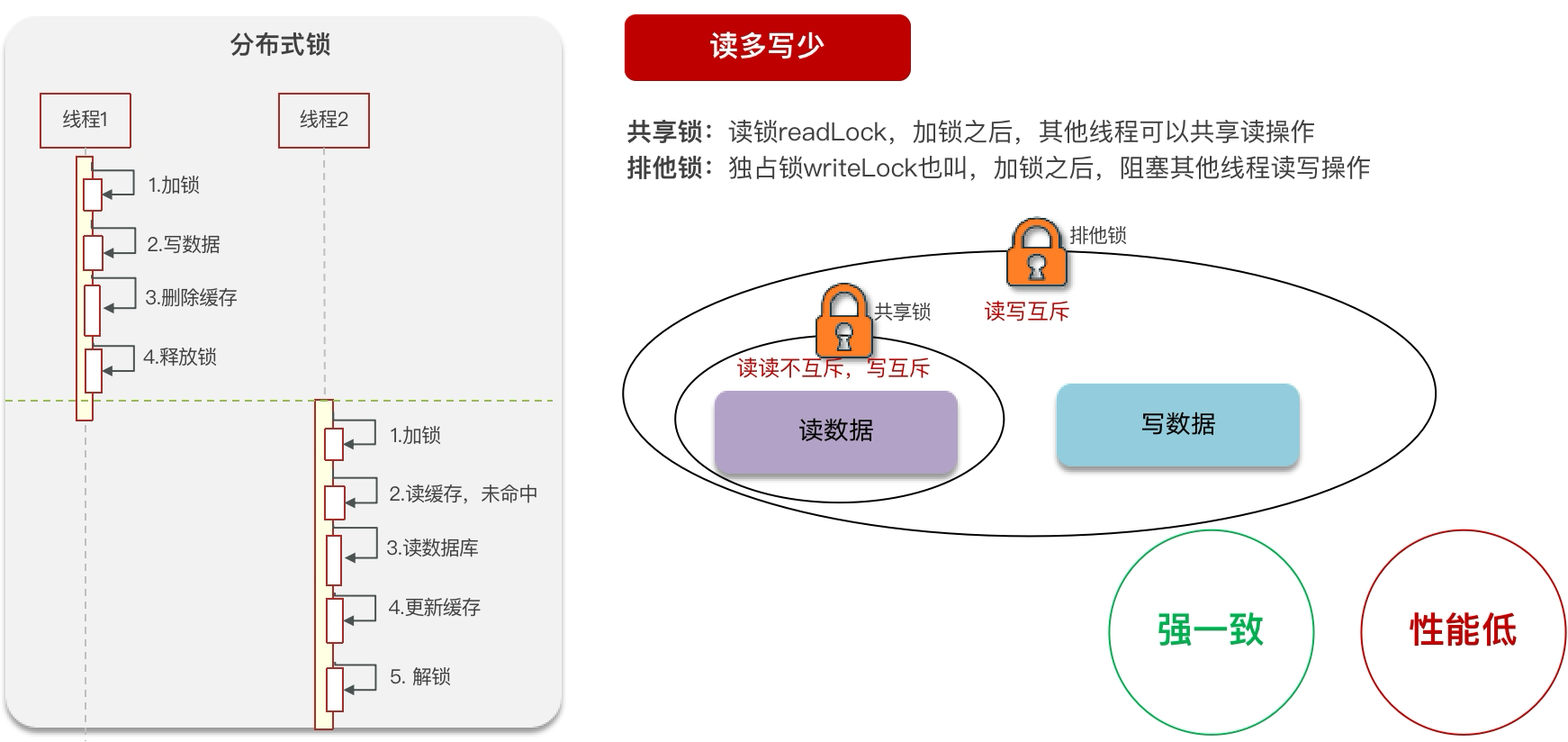
分布式锁的解决方案
使用分布式锁的方案性能太低,在读多写少的场景下使用的缓存可以使用读写锁来提高性能。但是读写锁在使用写锁时始终会阻塞其他的线程来读写。只有在强一致的场景下才会考虑。
具体的代码实现
public Shop getById(Long id) {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");
// 读之前加读锁,读锁的作用就是等待 LockKey 释放写锁以后再读
RLock rLock = rwLock.readLock();
try {
rLock.lock();
String shop_key = CACHE_SHOP_KEY + id;
String shopJson = redisTemplate.opsForValue().get(shop_key);
// 如果店铺信息不为空则返回店铺信息
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
// 如果店铺信息为空则查询店铺信息,不存在则返回报错
Shop shop = getById(id);
if (shop == null) {
redisTemplate.opsForValue().set(shop_key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 如果店铺存在则设置缓存并设置过期时间
redisTemplate.opsForValue().set(shop_key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
return shop;
} finally {
rLock.unlock();
}
}@Override
public Result updateShop(Shop shop) {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");
// 写之前加写锁,写锁加锁成功,读锁只能等待
RLock wLock = rwLock.writeLock();
try {
wLock.lock();
// 修改店铺信息
updateById(shop);
// 删除店铺缓存
redisTemplate.delete(CACHE_SHOP_KEY + shop.getId());
return Result.ok();
} finally {
wLock.unlock();
}
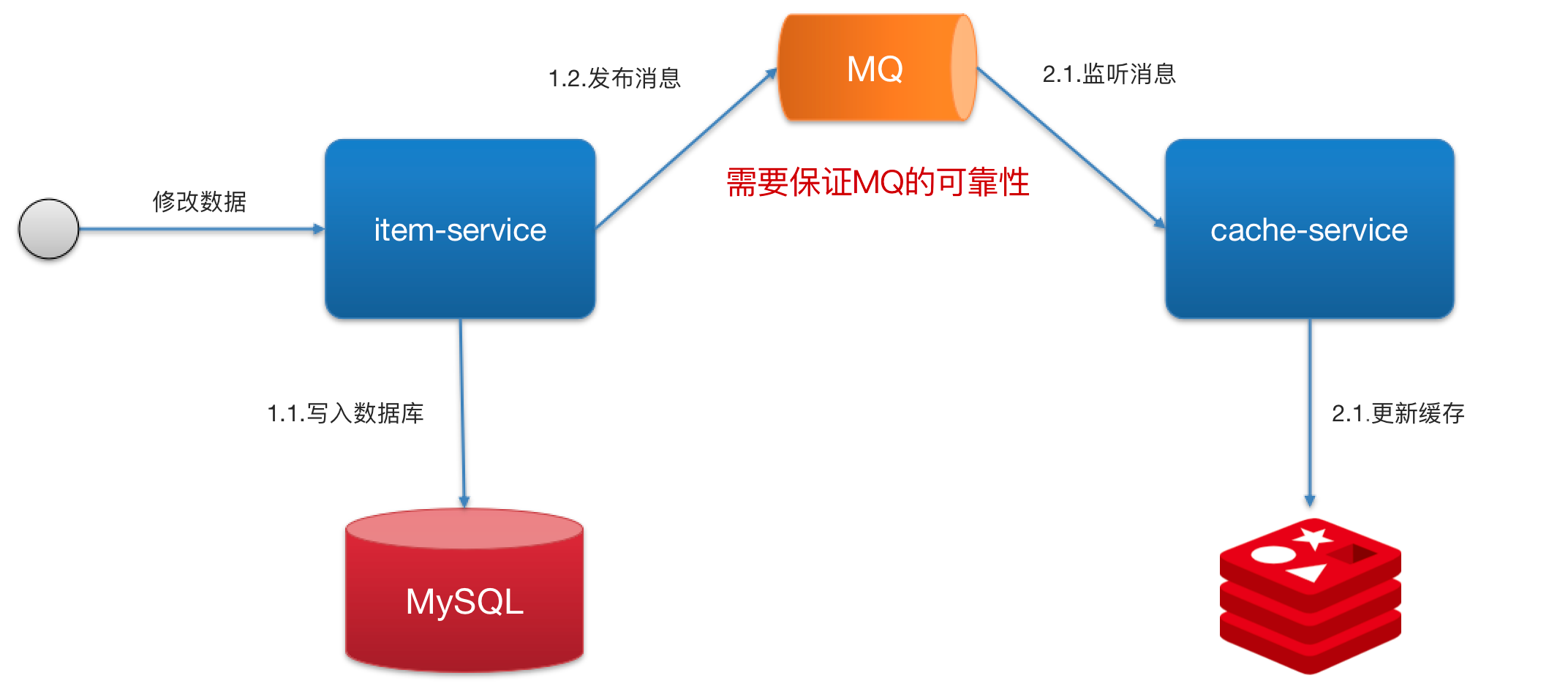
}异步通知保证数据最终的一致性
基于 MQ 的异步通知
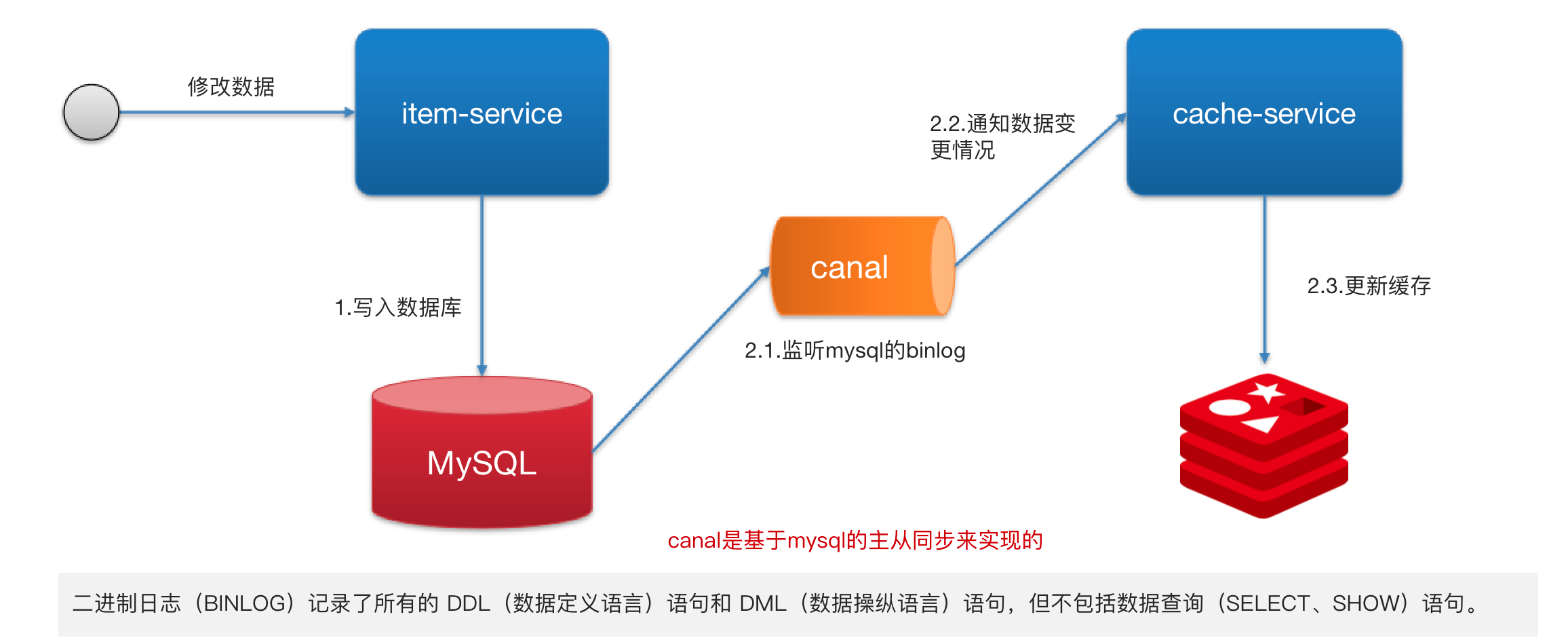
基于 Canal 的异步通知
💡思考:Redis 作为缓存,MySQL 的数据是如何与 Redis 进行同步的
- 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以,我们当时采用的是异步的方案同步的数据
- 我们当时是把抢券的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致,我们当时采用的是 Redisson 提供的读写锁来保证数据的同步
💡思考:介绍一下你们项目中采用的方案
允许延时一致的业务,采用异步通知
- 使用 MQ 中间件,更新数据之后,通知缓存删除利用
- 使用 Canal 中间件,不需要修改业务代码,伪装为 MySQL 的一个从节点,Canal 通过读取 binlog 数据更新缓存。
强一致性的,采用 Redisson 提供的读写锁
- 共享锁:读锁 ReadLock,加锁之后,其他线程可以共享读操作
- 排他锁:独占锁 WriteLock 也叫,加锁之后,阻塞其他线程读写操作
💡思考:你听说过延时双删吗?为什么不用它呢?
- 延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
分布式锁
Reids 分布式锁,是如何实现的?
需要结合项目中的业务进行回答,通常情况下,分布式锁使用的场景:集群情况下的定时任务、抢单、幂等性场景。
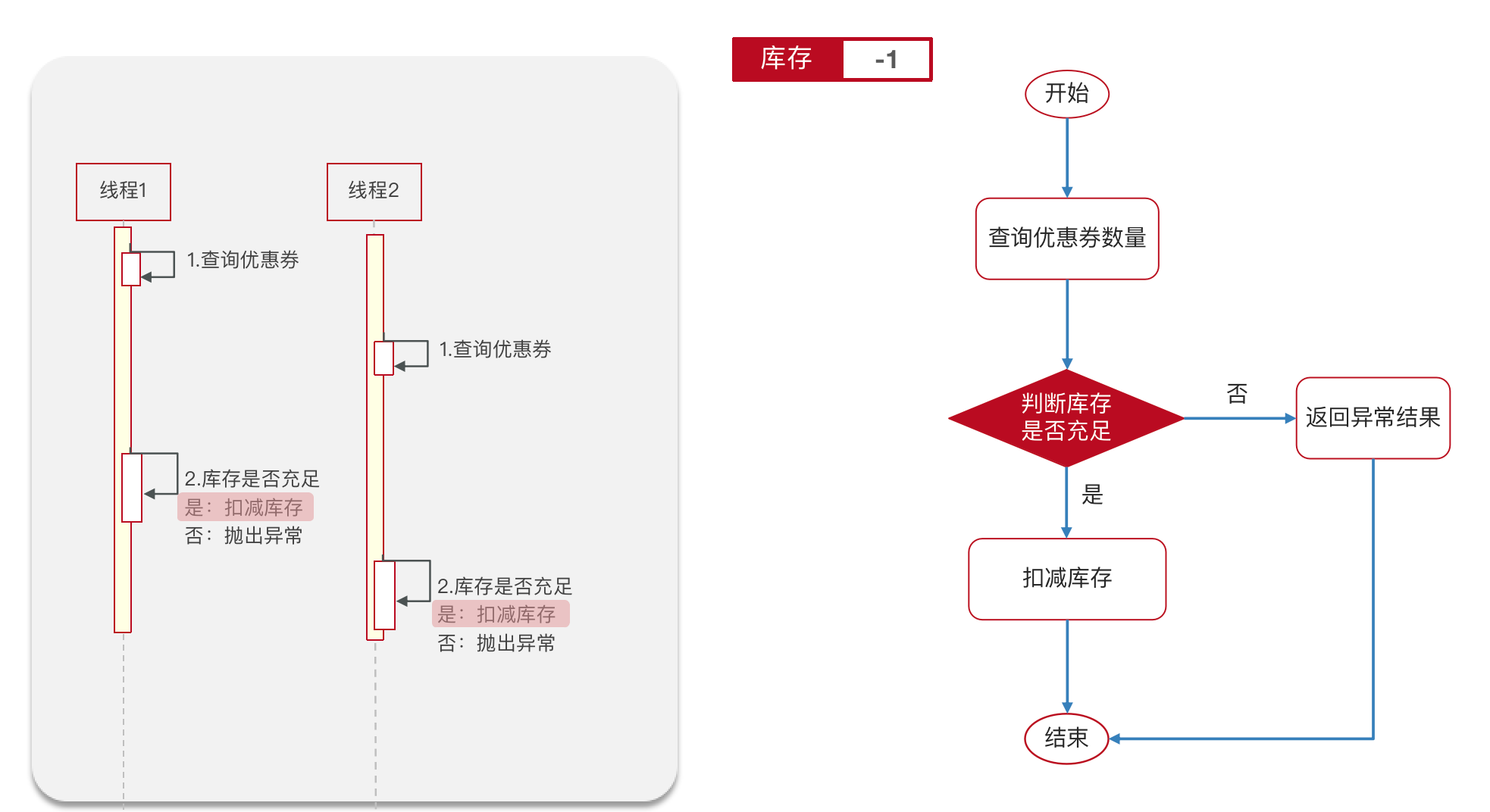
抢券场景
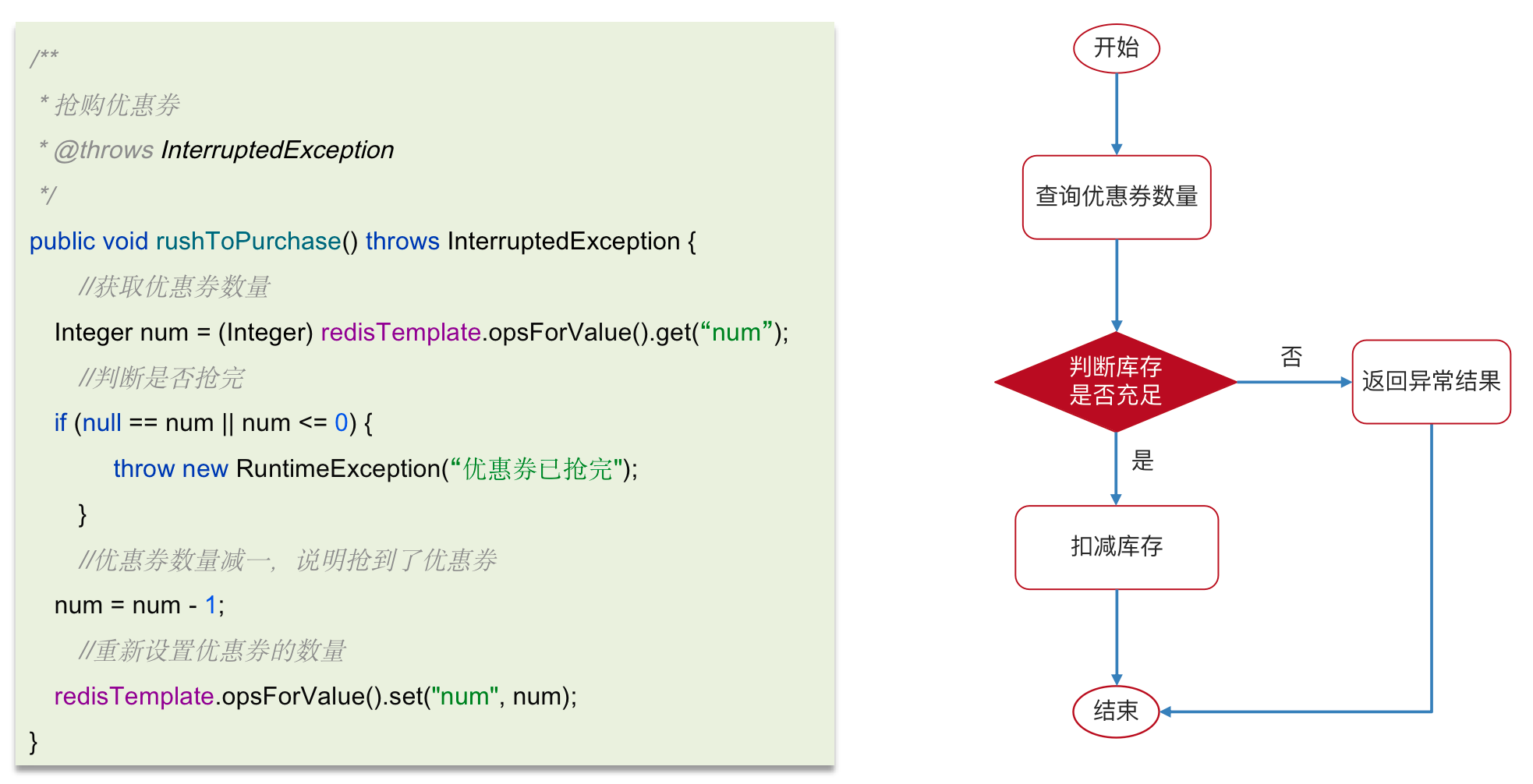
线程正常的处理流程,库存是会扣减到0
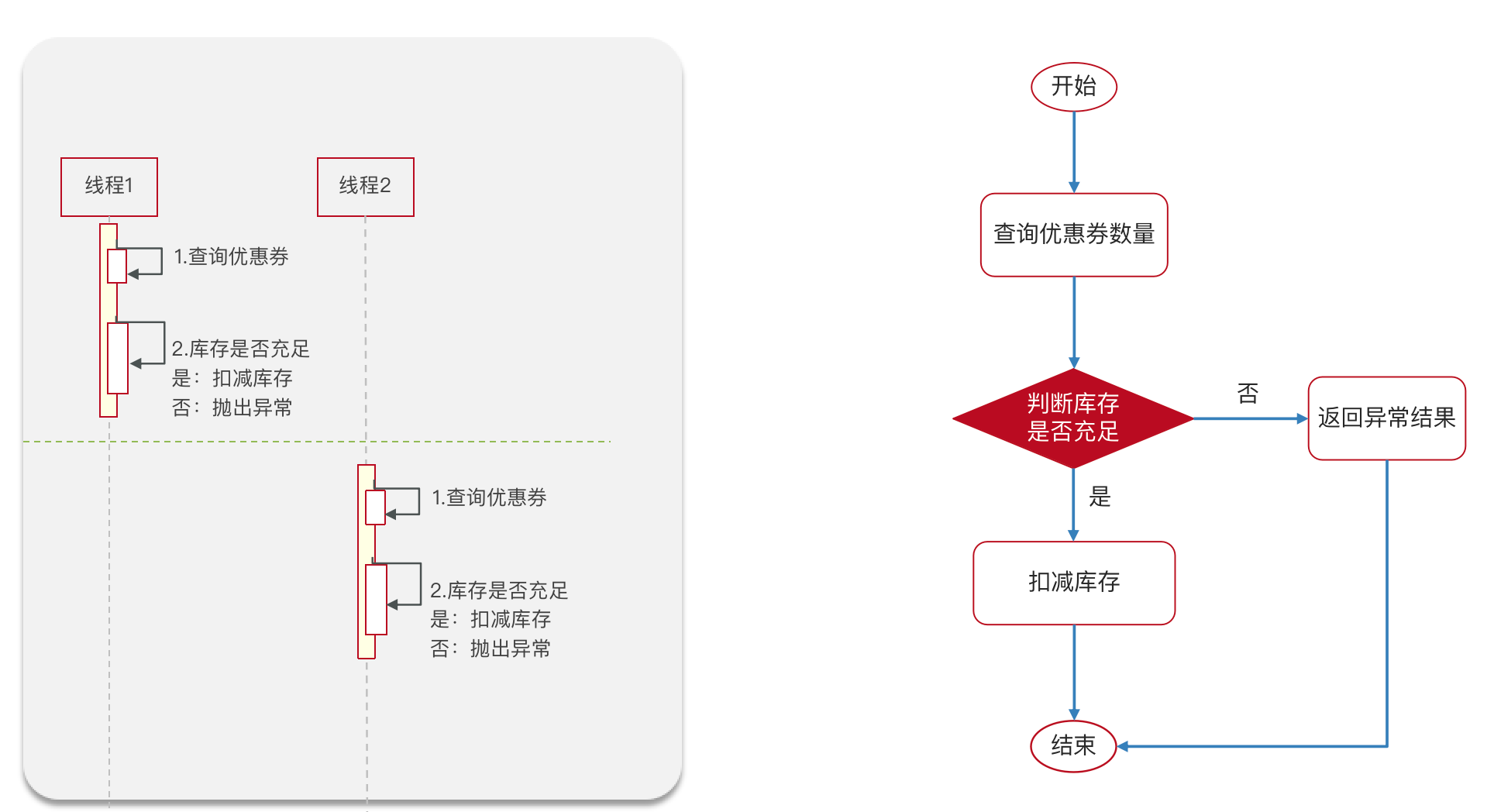
但是线程是交替执行的,有可能是以下执行的流程,库存变为-1,卖超了。
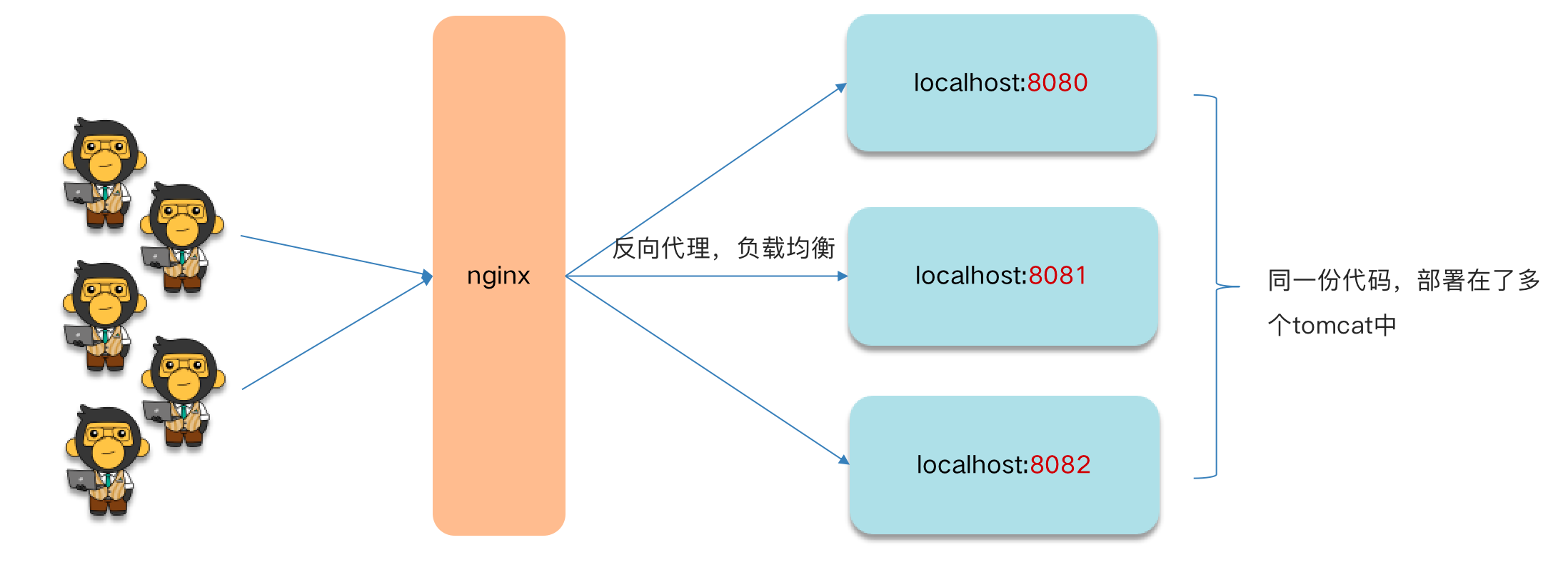
优化流程,为代码加上互斥锁。

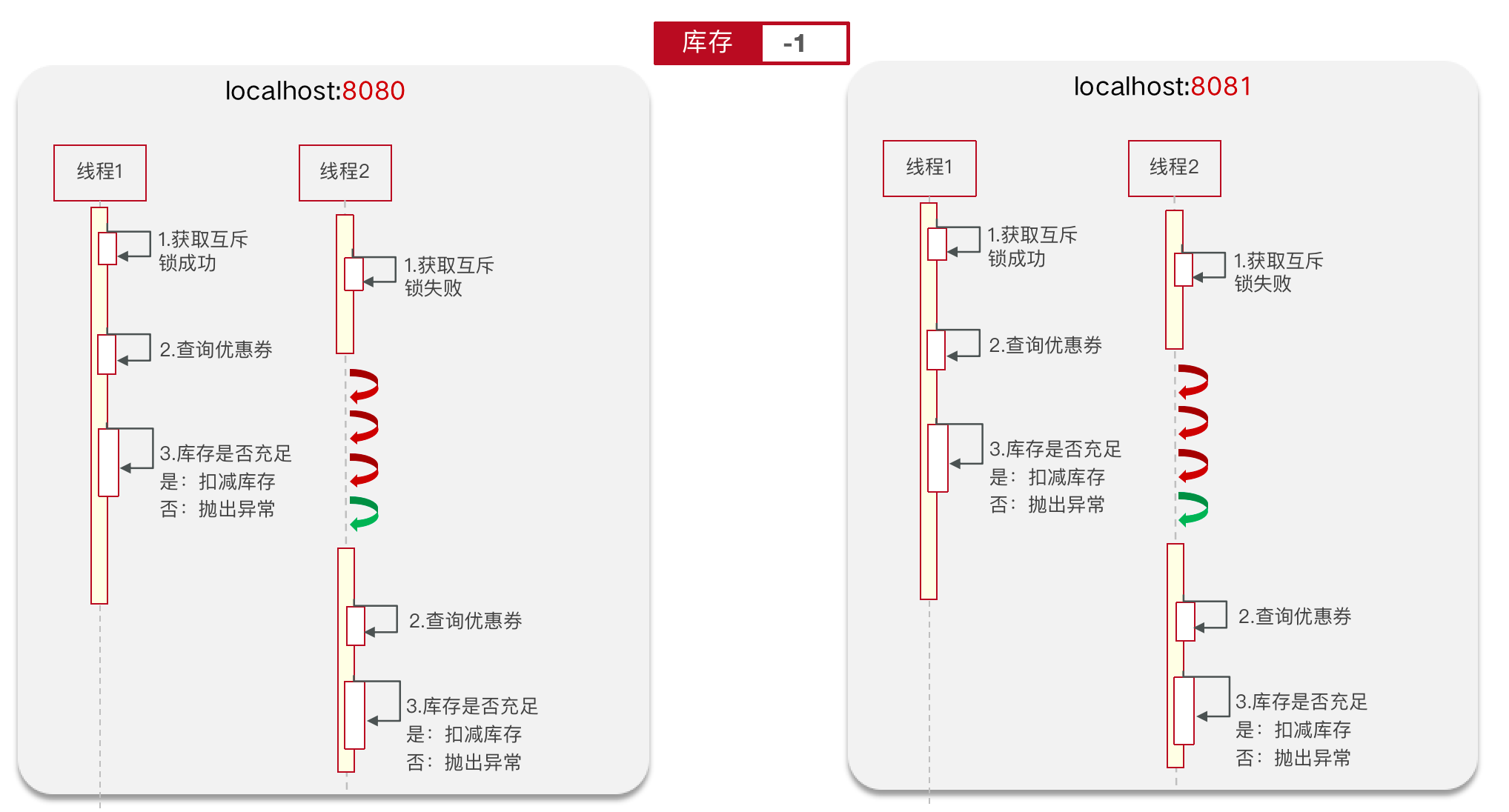
但是当我们服务是分布式部署的话,互斥锁只对自己服务生效。
库存又会重新变为-1
这个时候我们就需要通过分布式锁来解决多个服务器无法使用互斥锁。
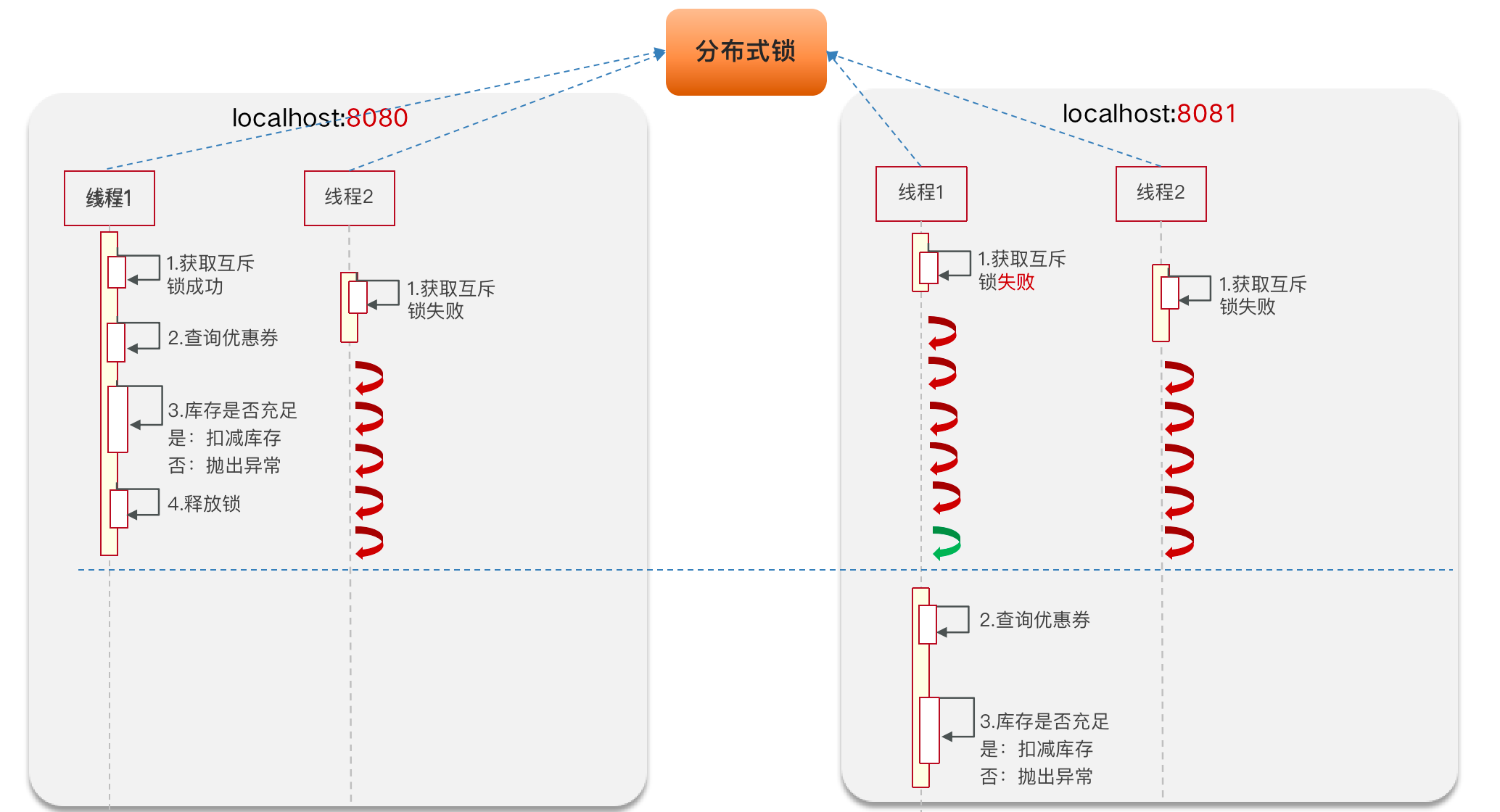
Redisson实现的分布式锁:主要是利用Redis的sentx命令。setnx 是 SET if not exists(如果不存在,则 SET)的简写。
# 添加锁,NX是互斥、EX是设置超时时间
SET key value NX EX 10
# 释放锁,删除即可
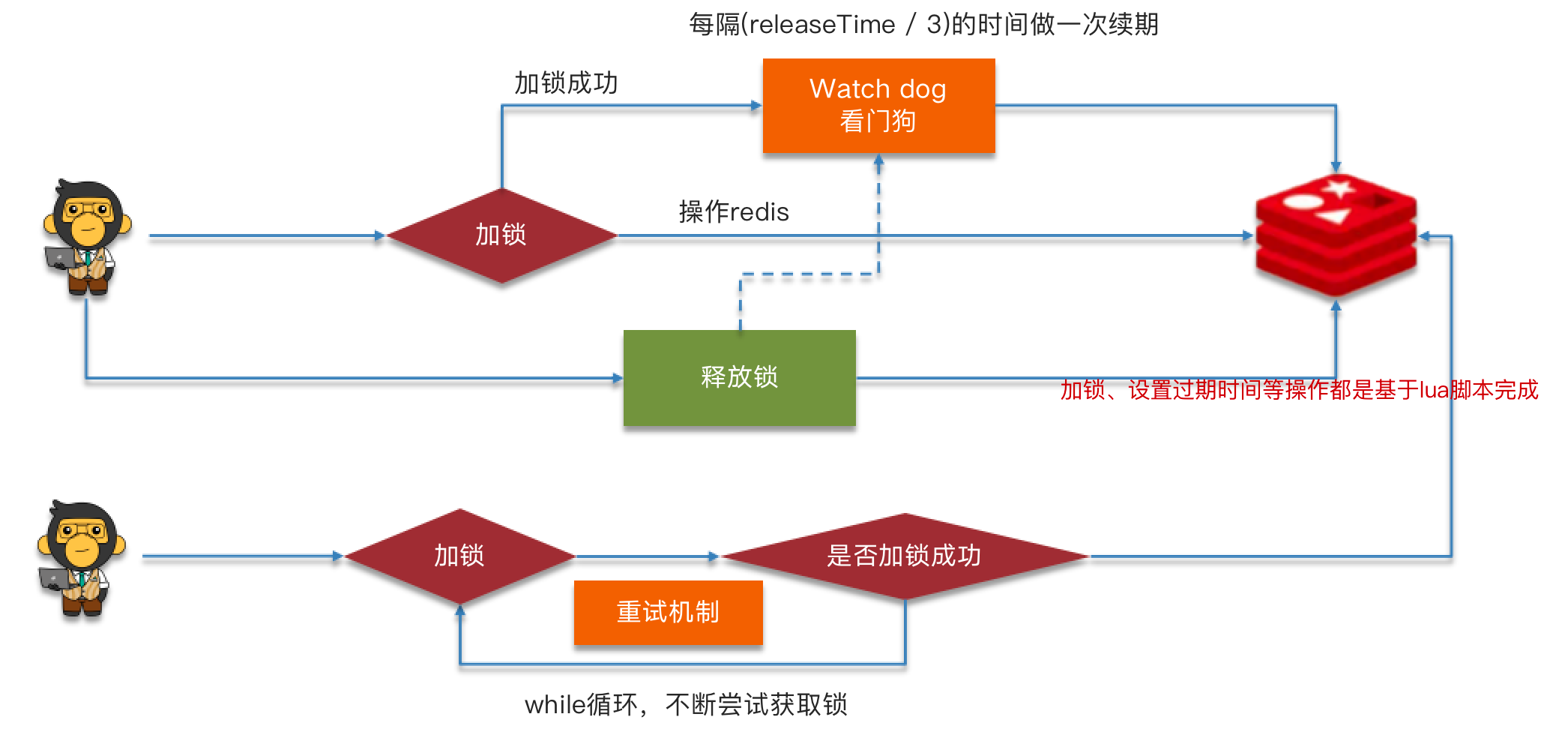
DEL keyRedis实现分布式锁如何合理的控制锁的有效时长?
- 根据业务执行时间预估。(不合理,网络卡顿等因素也会导致时间延长)
- 给锁续期。(
Watch Dog,根据业务执行的时间来控制锁的时间)
执行流程
具体使用代码:
@Test
void testRedisson() throws InterruptedException {
// 获取重入锁,执行锁的名称
RLock lock = redissonClient.getLock("order");
try {
/**
* 尝试获取锁,参数分别为:
* 获取锁的最大等待时间,期间会重试
* 锁自动释放时间
* 时间单位
*/
boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS);
boolean isLock = lock.tryLock(1, TimeUnit.SECONDS);
if (isLock) {
System.out.println("执行业务");
}
} finally {
lock.unlock();
}
}可重入

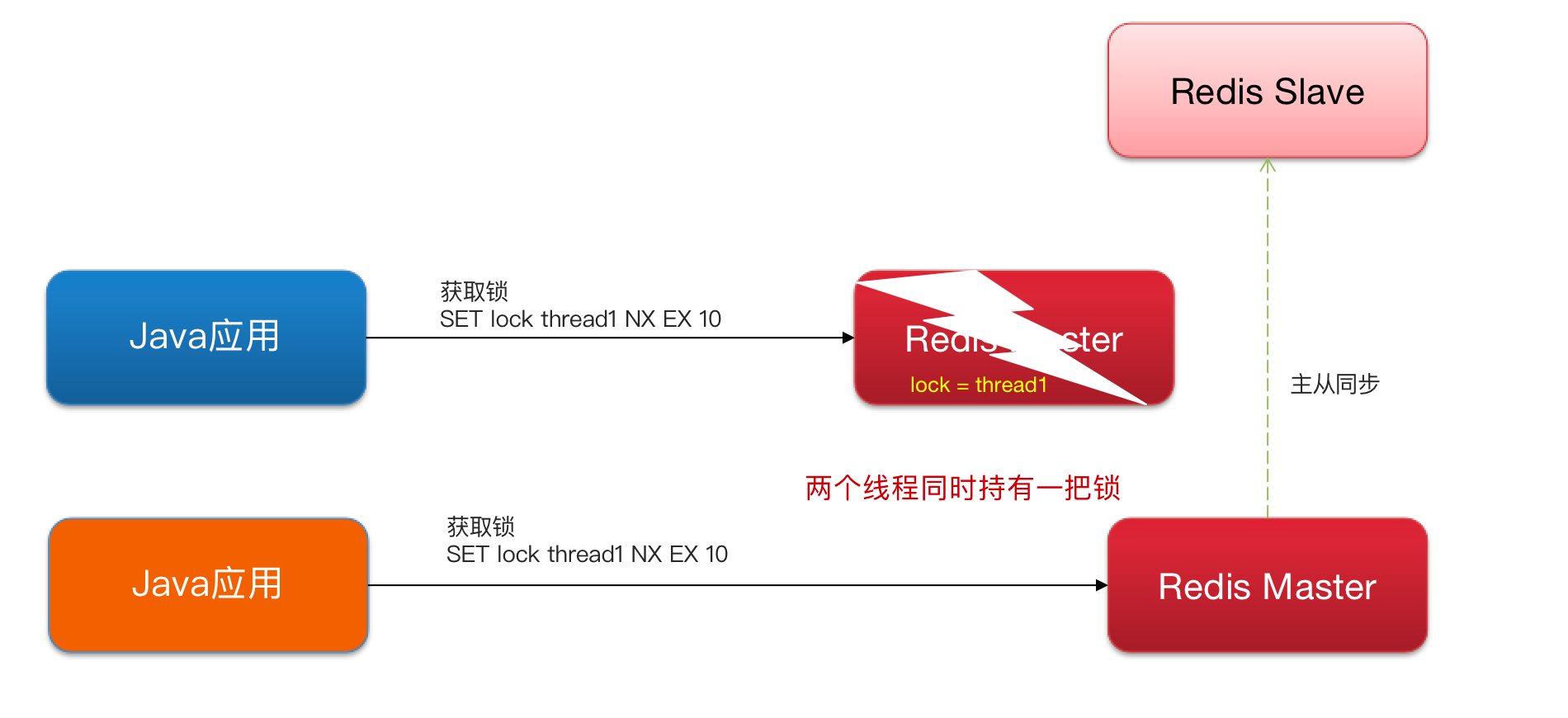
主从一致性
Java 应用一个线程在获取锁的时候宕机了,Redis 的主节点发生了转移,而这时 Java 应用的进程又获取了这个锁,导致两个进程同时持有一把锁。
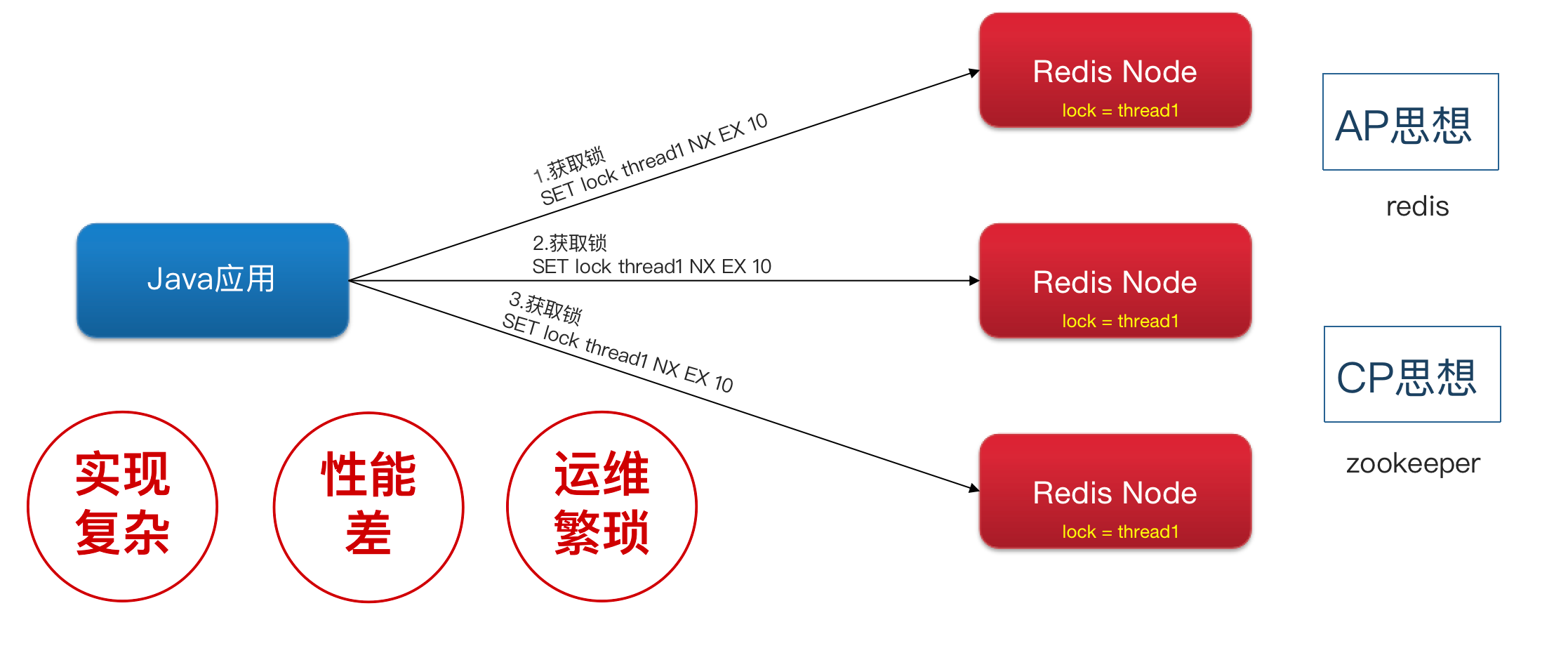
RedLock(红锁):不能只在一个 Redis 实例上创建锁,应该是在多个 Redis 实例上创建锁(n / 2 + 1),避免在一个Redis 实例上加锁。
💡思考:Redis 分布式锁如何实现 ?
我们系统是使用 Redisson 来实现的分布式锁,Redisson 底层是 setnx 和 Lua 脚本来实现的。因为 Redis 是单线程的,用了命令之后只能有一个客户端对 Key 进行设置值,当 Key 没有过期或者删除其他客户端都不能设置这个 Key。
💡思考:控制 Redis 实现分布式锁有效时长呢?
Redis 的 setnx 命令不好解决分布式锁的有效时长,我们是通过 Redisson 框架实现的。Redisson 中需要手动加锁,并且可以控制锁的失效时间和等待时间,当锁住的一个业务还没有执行完成的时候,Redisson 中就引入了一个看门狗机制,每隔一段时间就检查当前业务是否还持有锁,如果还持有就增加锁的持有时间,当业务执行完成以后可以直接就释放了。
Redisson 的锁中还有一个等待时间,可以在高并发的情况下很好的提升性能。就是当线程发生争抢后,没有抢到的线程不会马上拒绝,而是会自旋去尝试获取锁,当抢到的线程释放后,没有抢到的线程就可以尝试重新获取到锁。
💡思考:Redisson 实现的分布式锁是可重入的吗?
可以支持重入的,这是为了避免出现死锁情况。重入机制就是在内部判断是否是当前线程持有锁,如果是当前线程持有锁则计算就会加一,释放锁则会减一。在存储数据的时候是通过 Hash 结构,大 Key 是自己业务的锁的名称,小 Key 是线程唯一 ID, Value 是重入的次数。
💡思考:Redisson 实现的分布式锁能解决主从一致性的问题吗?
是不能的,比如,当线程一加锁成功后,从节点还没有获取到主节点同步的数据,主节点就宕机了,从节点被提升为新的主节点。假如现在来了一个线程二再次加锁,会在新的主节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用 Redisson 提供的红锁来解决这个问题,它的主要作用是,不能只在一个 Redis 实例上创建锁,应该是在多个 Redis 实例上创建锁,并且要求在大多数 Redis 节点上都成功创建锁,红锁中要求是 Redis 的节点数量要过半。这样就能避免线程1加锁成功后 Master 节点宕机导致线程2成功加锁到新的 Master节点上的问题了。
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变的很低了,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁。
💡思考:如果业务非要保证数据的强一致性,这个该怎么解决呢?
Redis 本身就是支持高可用的,做到强一致性,就非常影响性能。所以,如果有强一致性要求高的业务,建议使用 Zookeeper 实现的分布式锁,它是可以保证强一致性的。
高可用
持久化
RDB
全称 Redis Database Backup File(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,回复数据。
主动备份命令
[mousse@MacBookAir ~]$ redis-cli
127.0.0.1:6379> save
OK
127.0.0.1:6379> bgsave
Background saving startedRedis 内部有触发 RDB 的机智,可以在 redis.conf 文件中找到,格式如下:
# 900秒内,如果至少有1个key被修改,则执行bgsave
save 900 1
save 300 10
save 60 10000RDB执行原理
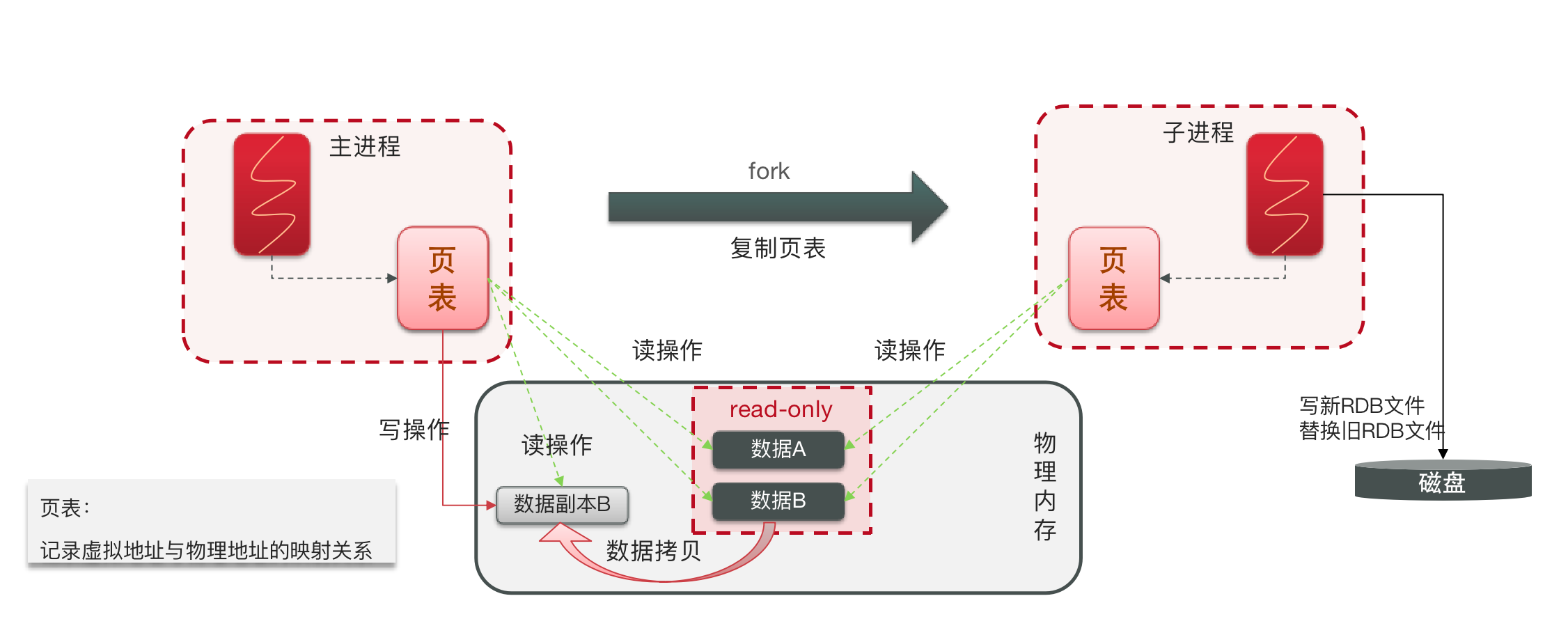
bgsave 开始时会 fork 主进程得到子进程,子进程共享主进程的内存数据。这里的内存数据是一个页表,页表存储的是虚拟地址与物理地址的映射关系,所以这个速度很快。完成 fork 后读取内存数据并写入RDB文件。
fork 采用的是 copy-on-write 技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。当主进程读是会读取修改后的数据。
AOF
AOF 全称为 Append Only File(追加文件)。Redis处理的每一个写命令都会记录在 AOF 文件,可以看做是命令日志文件。
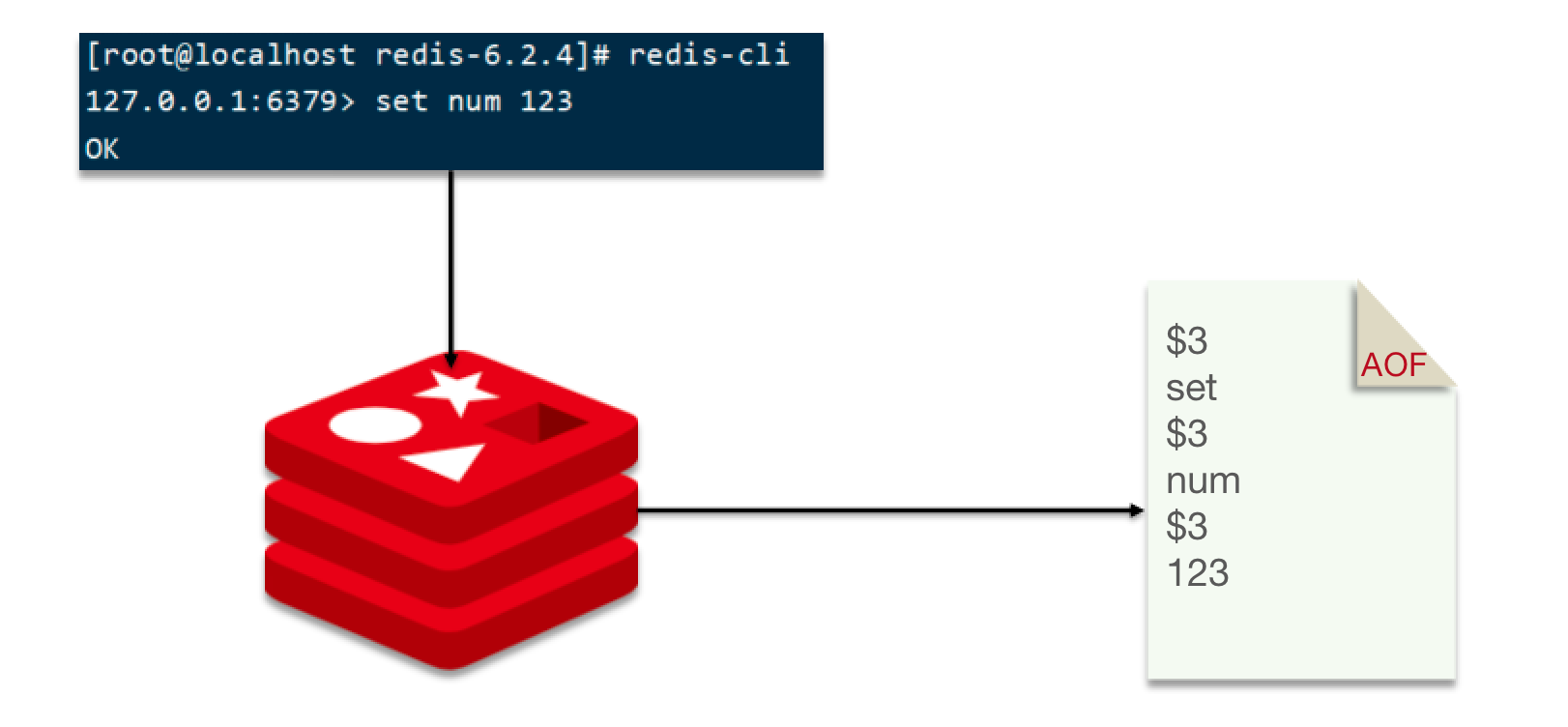
AOF 默认是关闭的,需要修改 redis.conf 配置文件来开启 AOF
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"AOF 的命令记录的也可以通过 redis.conf 文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
因为是记录命令,AOF 文件会比 RDB 文件大的多。而且 AOF 会记录对同一个key对多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

Redis 也会触发阈值时自动重写 AOF 文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
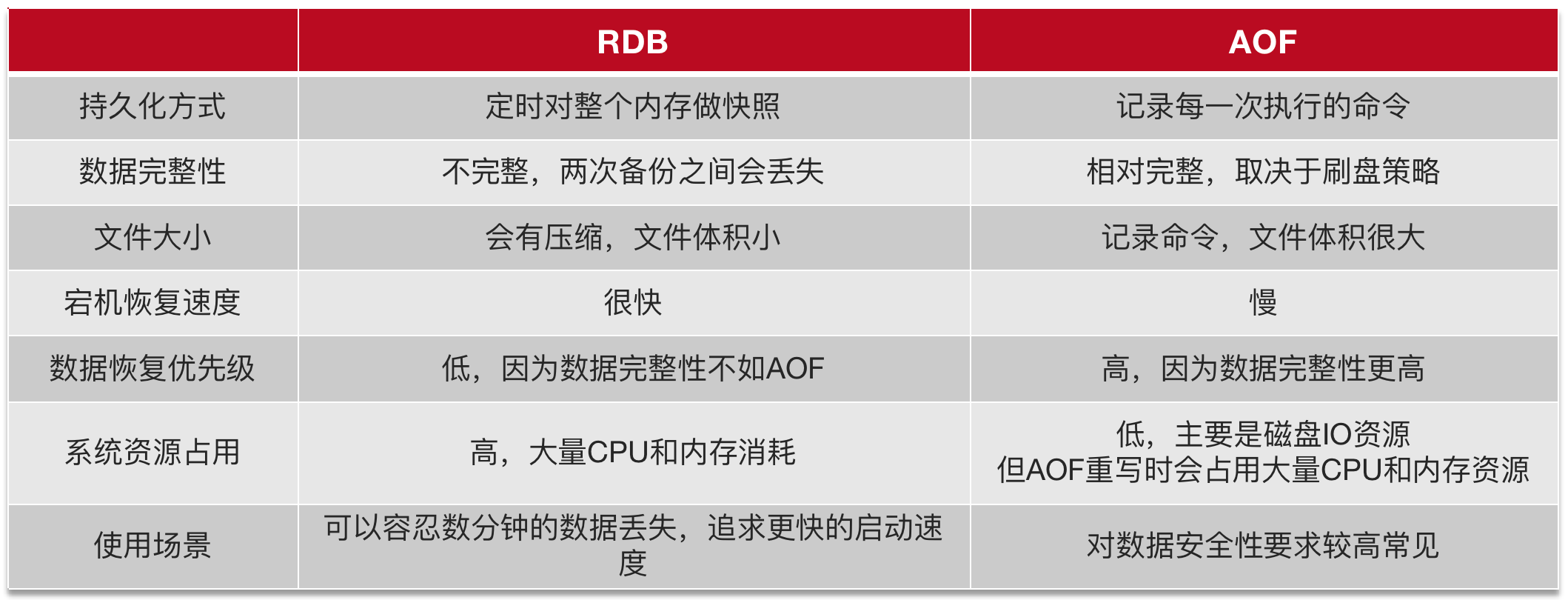
auto-aof-rewrite-min-size 64mbRDB与AOF对比:RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
Redis
💡思考:Redis 作为缓存,如何实现数据的持久化
Redis 数据持久化有两种方式,一种是 RDB,一种是 AOF。
- RDB 是一个快照文件,定期把 Redis 内存存储的数据写到磁盘上,当 Redis 宕机需要恢复数据的时候则通过 RDB 的快照文件进行恢复数据。
- AOF 是一个追加文件,将 Redis 执行写操作的命令存储在这个文件中,当 Redis 宕机需要恢复数据的时候,则通过 AOF 文件在执行一次命令。
在数据的恢复上,RDB 本身是一个二进制文件,恢复数据的效率会比较快,但是有可能会丢失数据。 AOF 丢数据的风险比较小,可以灵活的设置刷盘策略,但是恢复数据比较慢。在Redis 4.0 推出了混合持久化模式,结合了RDB 和 AOF 的优点,在 AOF 文件的前半部分包含了一个完整的快照数据,在 AOF 文件的后半部分记录了一个自生成 RDB 快照以来的所有写操作命令。 以提高数据恢复的效率和可靠性。
RDB 的执行原理你知道是什么吗?
Redis 在执行 bgsave 命令后,主进程会 fork 一个子进程,子进程共享主进程的内存数据。
内存数据是主进程维护了一个页表,页表是虚拟内存与物理内存的关系映射,所以子进程拷贝主进程的数据很快,是纳秒级别的。完成 fork 后写新的 RDB 文件并替换旧的 RDB文件。
fork 采用的是 copy-on-write 技术。当主进程有数据要读时共享读。当主进程写时则对内存数据进行复制,然后在复制上的数据进行修改。修改完成以后线程读取修改完成以后的数据。
拓展:Redis 7.0 Multi Part AOF的设计和实现-阿里云开发者社区
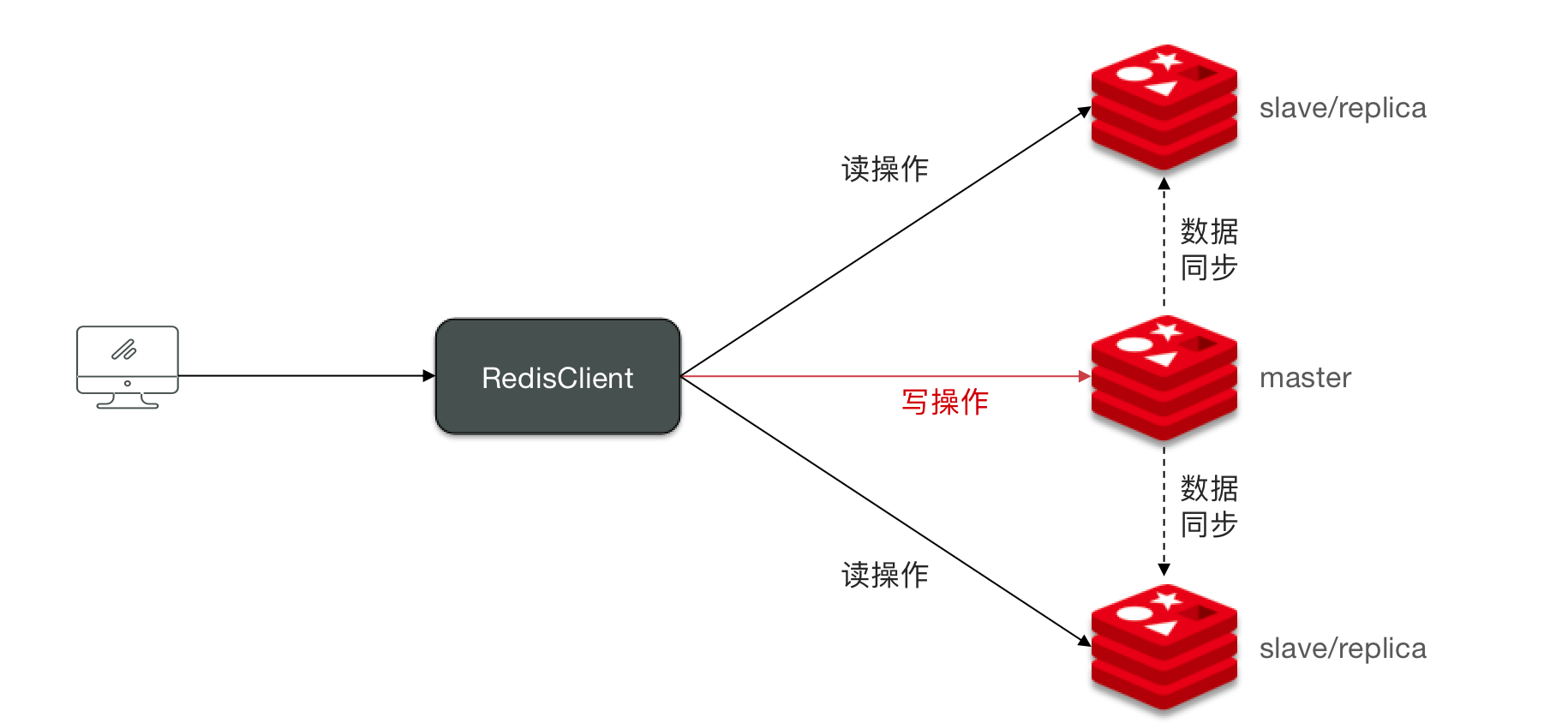
主从复制
单节点Redis的并发能力是有上线的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
主从全量同步
如何确认是第一次请求?发送数据的多少该如何确认?
Replication Id:简称 replid,是数据集的标记,id 一致则说明是同一数据集。每一个 master 都有唯一的 replid,slave 则会继承 master 节点的 replid。
offset:偏移量,随着记录在 repl_baklog 中的数据增多而逐渐增大。slave 完成同步时也会记录当前同步的 offset。如果 slave 的 offset 小于 master 的 offset,说明 slave 数据落后于 master,需要更新。
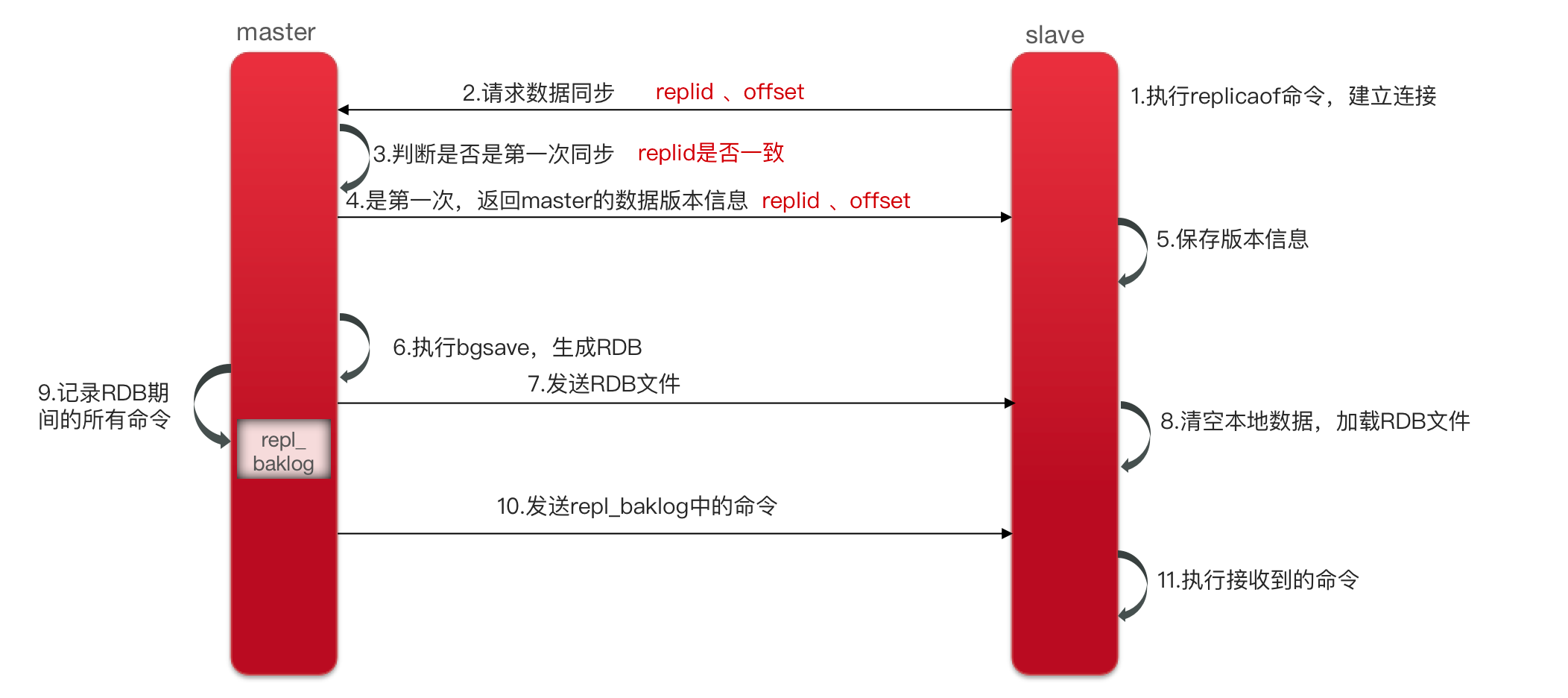
需要注意的点:
- 通过 replid 来判断是否是第一次同步,如果是第一次同步则会返回 replid 来标明是同一数据集,返回 offset 偏移量。
- 只有在第一次全量同步数据的时候才会返回 RDB 文件。
- 在执行 RDB 的时候,会通过 repl_baklog 来记录 RDB 期间的所有命令。往后增量同步都是通过返回 repl_baklog 中的命令。
主从增量同步
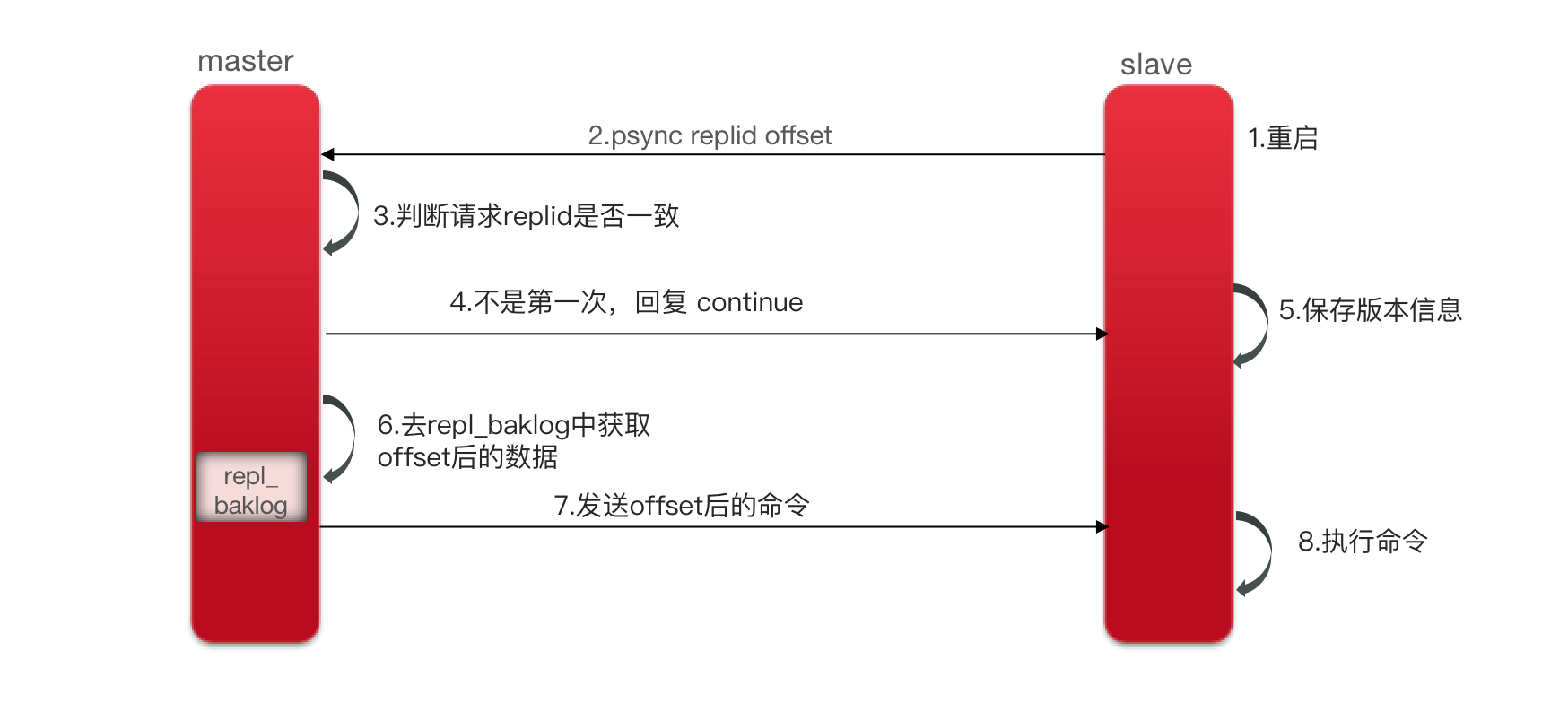
主从增量同步(slave重启或后期数据变化)
💡思考:什么是 Redis 主从同步,数据是怎么同步的?
主从同步的流程分为全量同步和增量同步。全量同步是从节点第一次和主节点建立连接的时候使用的,流程是
- 从节点请求主节点数据同步,并且从节点发送自己的
Replication id和offset偏移量 - 主节点判断是否和从节点是同一个
replication id,如果不是则说明是第一次全量同步;则主节点会将自己的replication id和offset发送给从节点,让从节点与主节点数据保持一致。 - 同时主节点会执行
bgsave命令,生成RDB文件给从节点去执行。从节点会先将自己数据清空,然后执行主节点发过来的RDB文件,这样数据就会保持一致。 - 当然在
RDB执行的过程中,依然有读写操作会请求到主节点,主节点会以命令的方式记录到缓冲区,缓冲区是一个日志文件,把这个日志文件发送到从节点,从而保证主从节点数据的一致性。
增量同步
- 当从节点重启服务后数据会不一致,从节点会向主节点同步数据,主节点判断
replication id是否一致。 - 一致则请求从节点的
offset值,将主节点的命令日志中获取offset值之后的数据,发送给从节点进行数据同步。
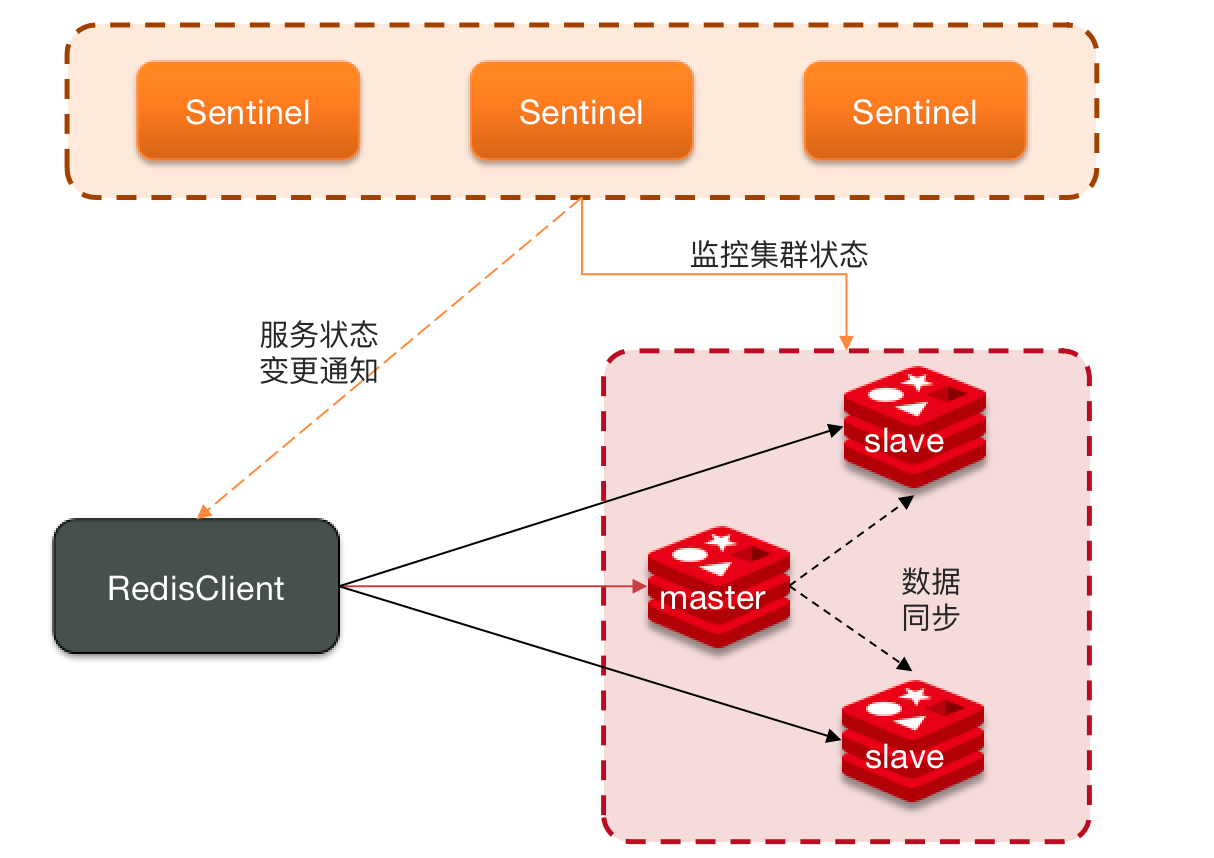
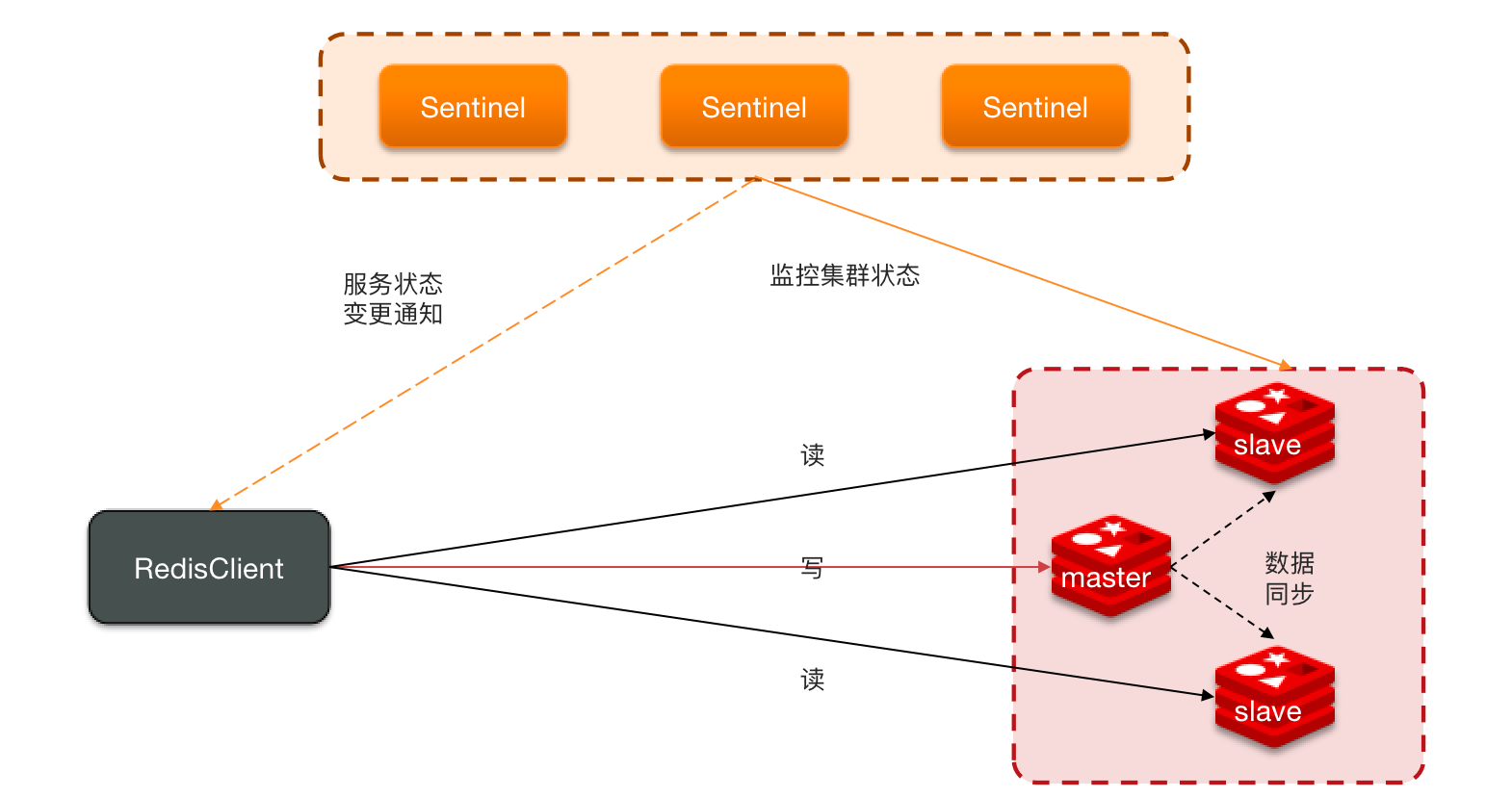
哨兵模式
Redis 提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
- 监控:Sentinel 会不断检查您的 master 和 slave 是否按预期工作。
- 通知:Sentinel 充当 Redis 客户端的服务来发现来源,当集群发生故障转移时,会将最新信息推送给 Redis 客户端。
- 自动故障恢复:如果 master 故障,Sentinel 会将一个 slave 提升为 master。当故障实例恢复后也以新的 master 为主。
服务状态监控
Sentinel 基于心跳机制监测服务状态,每隔1秒向集群的每隔实例发送ping命令:
- 主观下线:如果某 Sentinel 节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的 Sentinel 都认为该实例主观下线,则该实例客观下线。quorum 值最好超过 Sentinel 实例数量的一半。
哨兵选主规则
- 首先判断主与从节点断开时间长短,如超过指定值就排该从节点
- 然后判断从节点的 slave-priority 值,越小优先级越高
- 如果 slave-prority 一样,则判断 slave 节点的 offset 值,越大优先级越高
- 最后是判断 slave 节点的运行 id 大小,越小优先级越高。
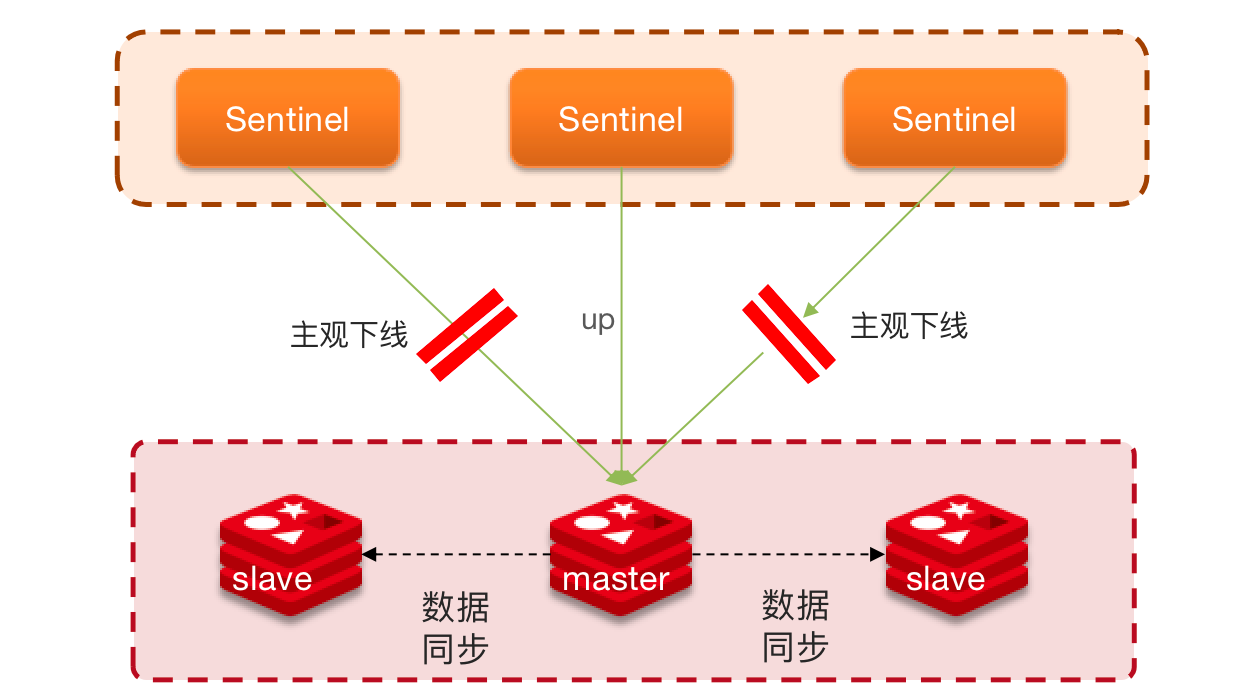
集群脑裂
正常的主从架构,配合了哨兵模式
如果主节点和从节点因为网络的原因在不同的网络分区。哨兵就会根据选主规则将从节点中选出一个座位主节点,但是原先的主节点并没有挂,只是因为网络波动。这就像大脑分裂出了一个,形成脑裂现象。
因为网络还没有恢复,数据还会将数据写到原先的主节点,新的主节点无法同步数据。
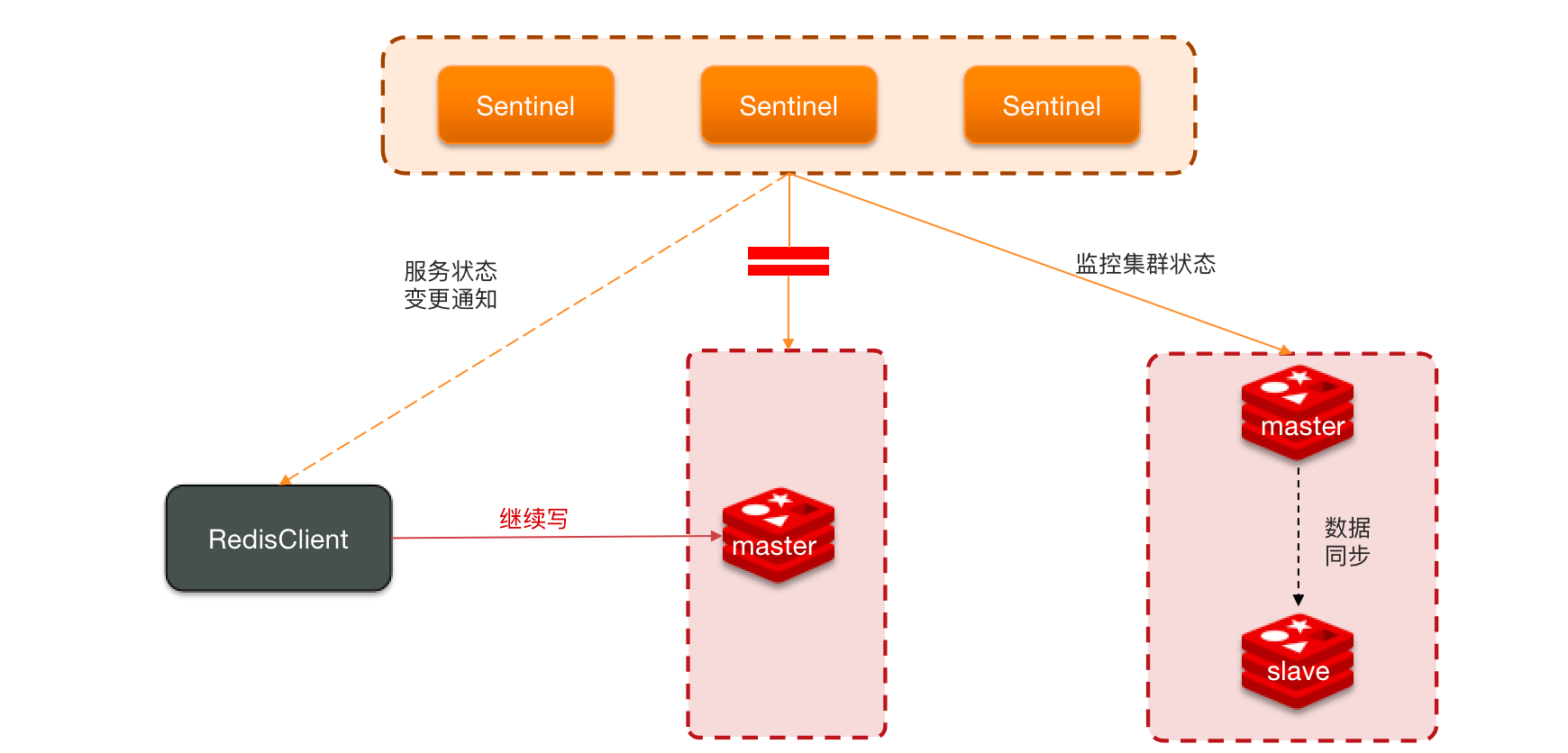
当网络恢复后,原先的 master 节点会降为 slave 节点并将原先的数据清空。但是在原先的脑裂过程中,在客户端写入的数据则会丢失。
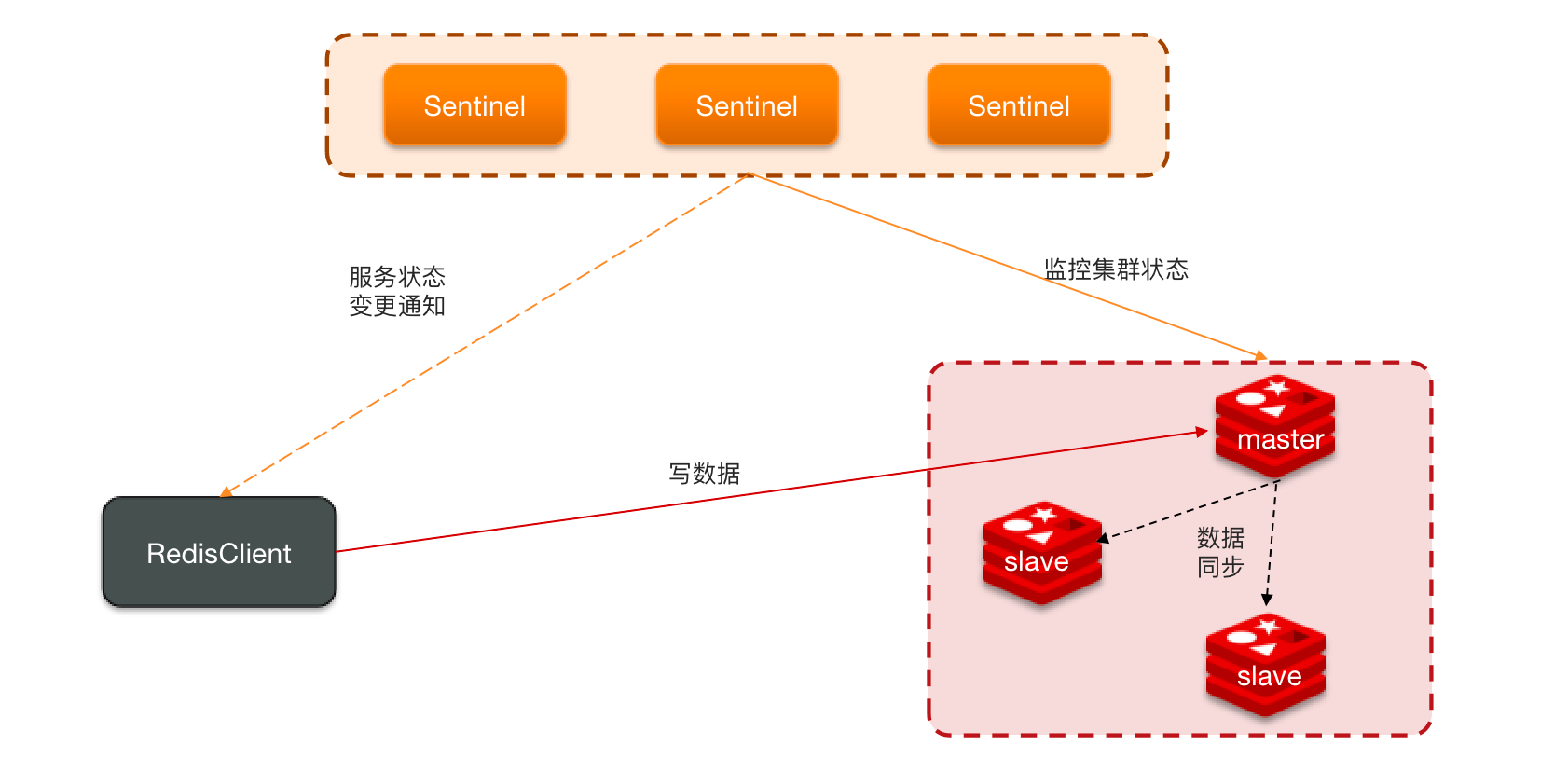
可以通过 Redis 中有两个配置参数来解决脑裂问题
# 表示最少的salve节点为1个才能接受客户端的数据。
min-replicas-to-write 1
# 表示数据复制和同步的延迟不能超过5秒,否则就拒绝客户端的请求。
min-replicas-max-lag 5总结
面试官:怎么保证Redis的高并发高可用
哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
你们使用 Redis 是单点还是集群,哪种集群
主从(一主一从)加哨兵就可以了。单节点不超过 10G 内存,如果 Redis 内存不足则可以给不同服务器分配独立的 Redis 主从节点。Redis 单节点的读并发在10w 左右,单节点的写在 8w 左右。
Redis 集群脑裂,该如何解决?
集群脑裂是由于主节点和从节点和哨兵处于不同的网络分区,使得哨兵没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个主节点,就像大脑分裂了一样,这样会导致客户端还在老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,哨兵会将老的主节点降为从节点,这时再从新 master 同步数据,就会导致数据丢失
解决:我们可以修改 Redis 的配置,可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失
💡思考:怎么保证 Redis 的高并发高可用
首先可以搭建主从集群,再加上使用 Redis 中的哨兵模式,哨兵模式可以实现主从集群的自动故障恢复,里面就包含了对主从服务的监控、自动故障恢复、通知;如果主节点故障,哨兵会将一个从节点提升为主节点。当故障实例恢复后也以新的主节点为主;同时哨兵也充当 Redis 客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给 Redis 的客户端,所以一般项目都会采用哨兵的模式来保证 Redis 的高并发高可用。
💡思考:项目使用 Redis 是单点还是集群,哪种集群?
我们当时使用的是一主两从三哨兵。一般单节点不超过 10G 内存,如果 Redis 内存不足则可以给不同服务分配独立的 Redis 主从节点。尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用 Lua 脚本和事务。
💡思考:Redis 集群脑裂,该怎么解决呢?
有的时候由于网络等原因可能会出现脑裂的情况,就是说,由于 Redis 主节点和 Redis 从节点和哨兵处于不同的网络分区,使得哨兵没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主节点,这样就存在了两个主节点,就像大脑分裂了一样,这样会导致客户端还在原先的主节点那里写入数据,新节点无法同步数据,当网络恢复后,哨兵会将原先的主节点降为从节点,这时再从新主节点同步数据,这会导致脑裂过程中写入的数据丢失。
Redis的配置中可以设置:第一可以设置最少的 Salve 节点个数,比如设置至少要有一个从节点才能同步数据,第二个可以设置主从数据复制和同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失
分片集群
主从哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题。
- 高并发写的问题。
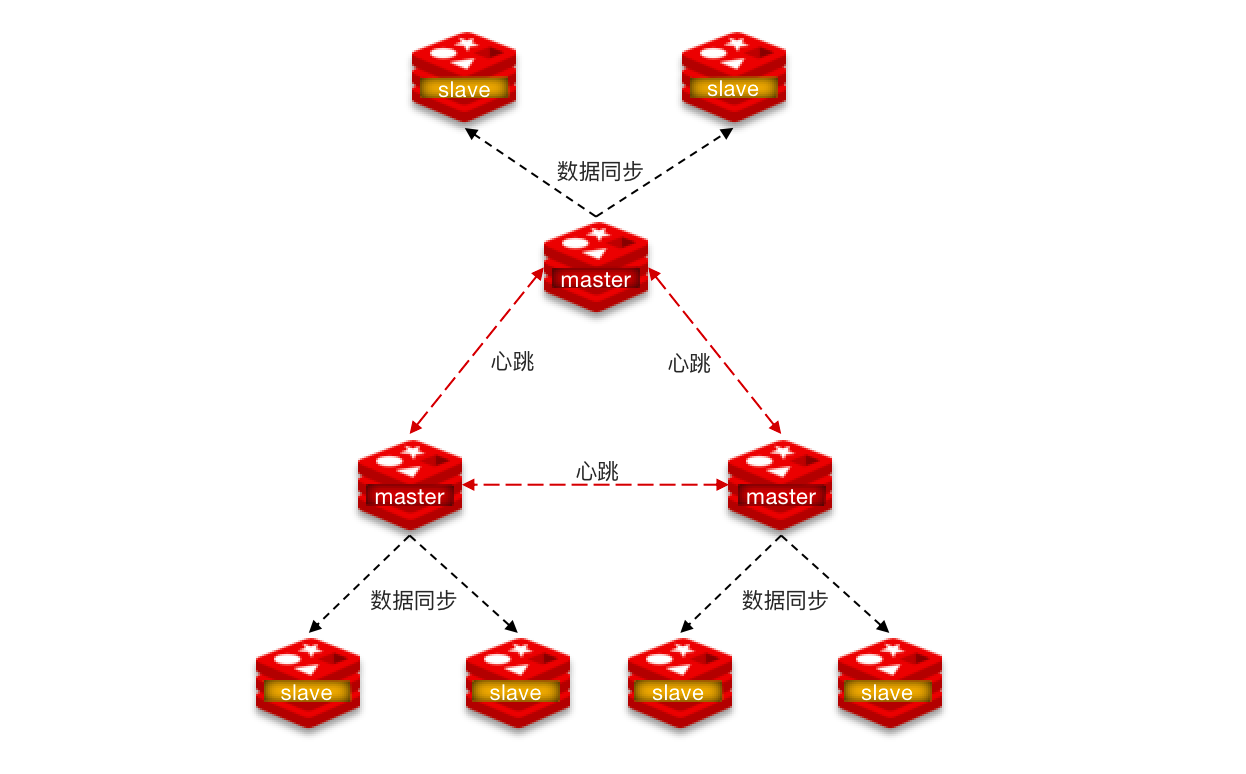
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个 master,每个 master 保存不同数据。
- 每个 master 都可以有多个 slave 节点。
- master 之间通过 ping 监测彼此健康状态。
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
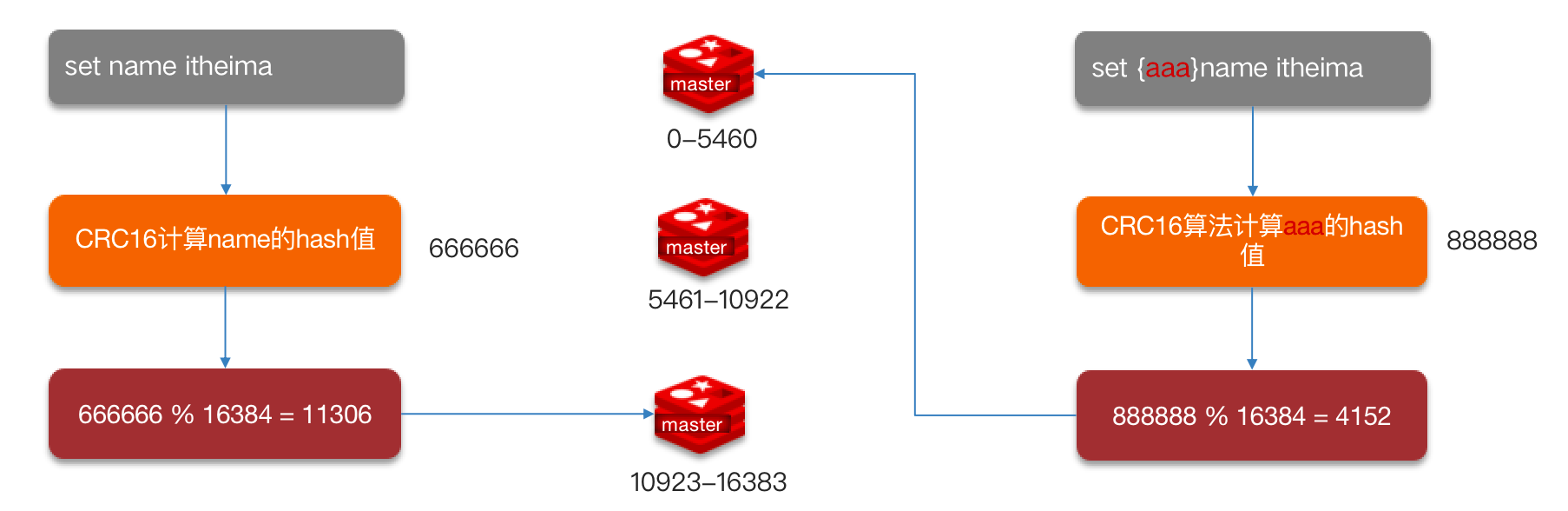
数据读写
Redis分片集群引入了哈希槽点概念,Redis集群有16384个哈希槽 (2^14^=16384),每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
💡思考:Redis的分片集群有什么作用
分片集群主要解决的是,海量数据存储和高并发写的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
💡思考:Redis分片集群中数据是怎么存储和读取的?
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围, key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,通过槽找到对应的节点进行存储。
Redis高级
过期策略
假如 Redis 的 Key 过期之后,会立即删除吗?
Redis 对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。删除策略有惰性删除和定期删除。
惰性删除
设置该 Key 过期时间后,我们不用管它,当需要该 Key 时,我们在检查是否过期,如果过期,我们就删掉它,反之返回该 Key。
set name zhangsan 10
get name // 发现 name 过期直接删除 key- 优点:对CPU友好,只会在使用该 Key 时才会进行过期检查,对于很多用不到的 Key 不用浪费时间进行过期检查。
- 缺点:对内存不友好,如果一个 Key 已经过期,但是一直没有使用,那么该 Key 就会一直存在内存中,内存永远不会释放。
定期删除
每隔一段时间,我们就会对一些 Key 进行检查,删除里面过期的 Key(从一定数量的数据库中取出一定数量的随机 Key 进行检查,并删除其中的过期 Key)。
定期清理有两种模式
- SLOW 模式是定时任务,执行评论默认为 10hz(每秒执行10次),每次不超过 25ms(尽量少的影响主进程操作),可以通过修改配置文件
redis.conf的 hz 选项来调整这个次数。 - FAST 模式执行评率不固定,但两次间隔不低于 2ms,每次耗时不超过 1ms。
- 优点:可以通过限制删除操作执行的时长和频率来减少删除操作对CPU的影响。并且定期删除也能有效释放过期占用的内存。
- 缺点:难以确定删除操作执行的时长和频率。
Redis 的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用。
淘汰策略
数据淘汰策略:当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称为内存的淘汰策略。
Redis支持8种不同策略来选择要删除的Key:
noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰allkeys-random:对全体key ,随机进行淘汰。volatile-random:对设置了TTL的key ,随机进行淘汰。allkeys-lru: 对全体key,基于LRU算法进行淘汰。- LRU(Least Recently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- 举例:key1是在3s之前访问的,key2是在9s之前访问的,删除的就是key2。
volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰。allkeys-lfu: 对全体key,基于LFU算法进行淘汰。- LRU (Least Frequently Used)最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
- 举例:key1最近5s访问了4次,key2最近5s访问了9次,删除的就是key1。
volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰。
使用建议
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
💡思考:Redis 的数据过期策略有哪些 ?
第一种是惰性删除,每次查找 Key 时判断是否过期,如果过期则删除
第二种是定期删除,定期抽样部分 Key,判断是否过期,如果过期则删除。
- SLOW 模式执行频率默认为10,每次不超过 25ms (高吞吐)
- FAST 模式执行频率不固定,但两次间隔不低于 2ms,每次耗时不超过 1ms(低延迟)
Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用。
💡思考:Redis的数据淘汰策略有哪些 ?
嗯,这个在 Redis中提供了很多种,默认是不删除任何数据,内部不足直接报错。可以在配置文件中进行设置,里面有两个非常重要的概念,一个是LRU,另外一个是LFU
LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
使用建议
- 如果业务没有冷热数据区分,访问频率差别不大,建议选择 allkeys-random,随机选择淘汰
- 如果业务有冷热数据区分,根据访问时间来淘汰,建议使用 allkeys-lru,把最近访问的数据留在缓存中。
- 如果有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
- 如果业务中有指定的需求,则可以使用 volaitle-ttl 。置顶数据设置不过期,不会被删除,淘汰设置过期时间的数据
网络协议
面试官:Redis是单线程,但是为什么还那么快。
- Redis是纯内存操作,执行速度非常快
- 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
- 使用I/O多路复用模型,非阻塞IO
面试官:能解释一下I/O多路复用模型?
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度, I/O多路复用模型主要就是实现了高效的网络请求。
- 用户空间和内核空间
- 常见的IO模型
- 阻塞IO(Blocking IO)
- 非阻塞IO(Nonblocking IO)
- IO多路复用(IO Multiplexing)
- Redis 网络模型
用户空间和内核空间
Linux系统中一个进程使用的内存情况划分为两部分:内核空间和用户空间
- 用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问。
- 内核空间可以执行特权命令(Ring0),调用一切系统资源。
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
- 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
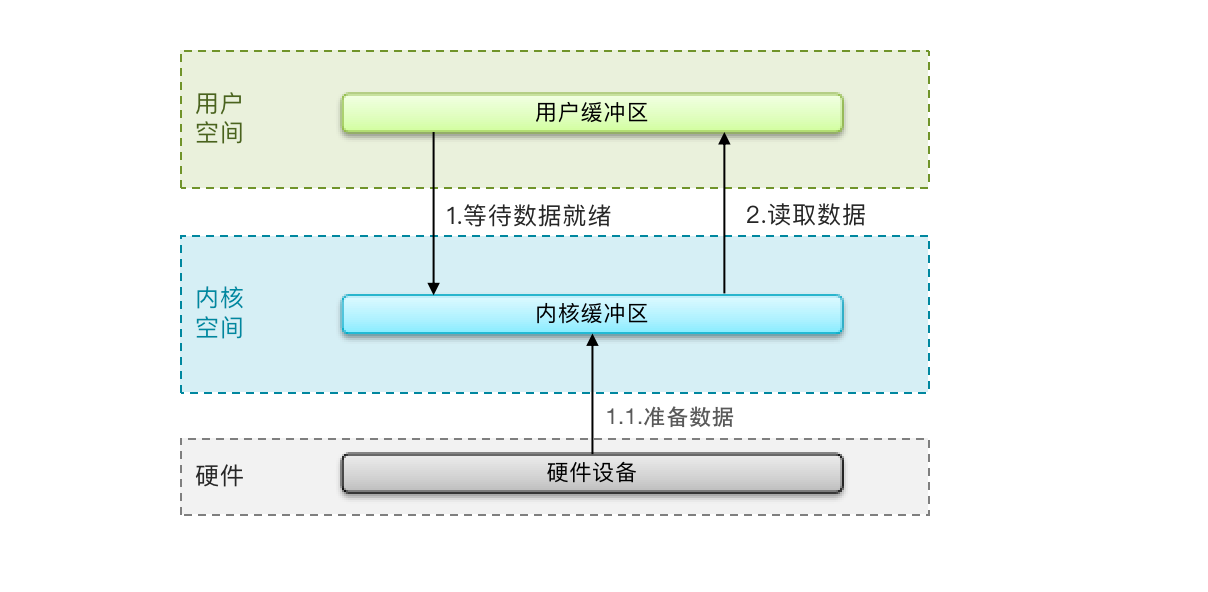
阻塞IO
顾名思义,阻塞IO就是两个阶段都必须阻塞等待
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未达到,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
可以看到,阻塞IO模型中,用户进程在两个阶段都是阻塞状态。
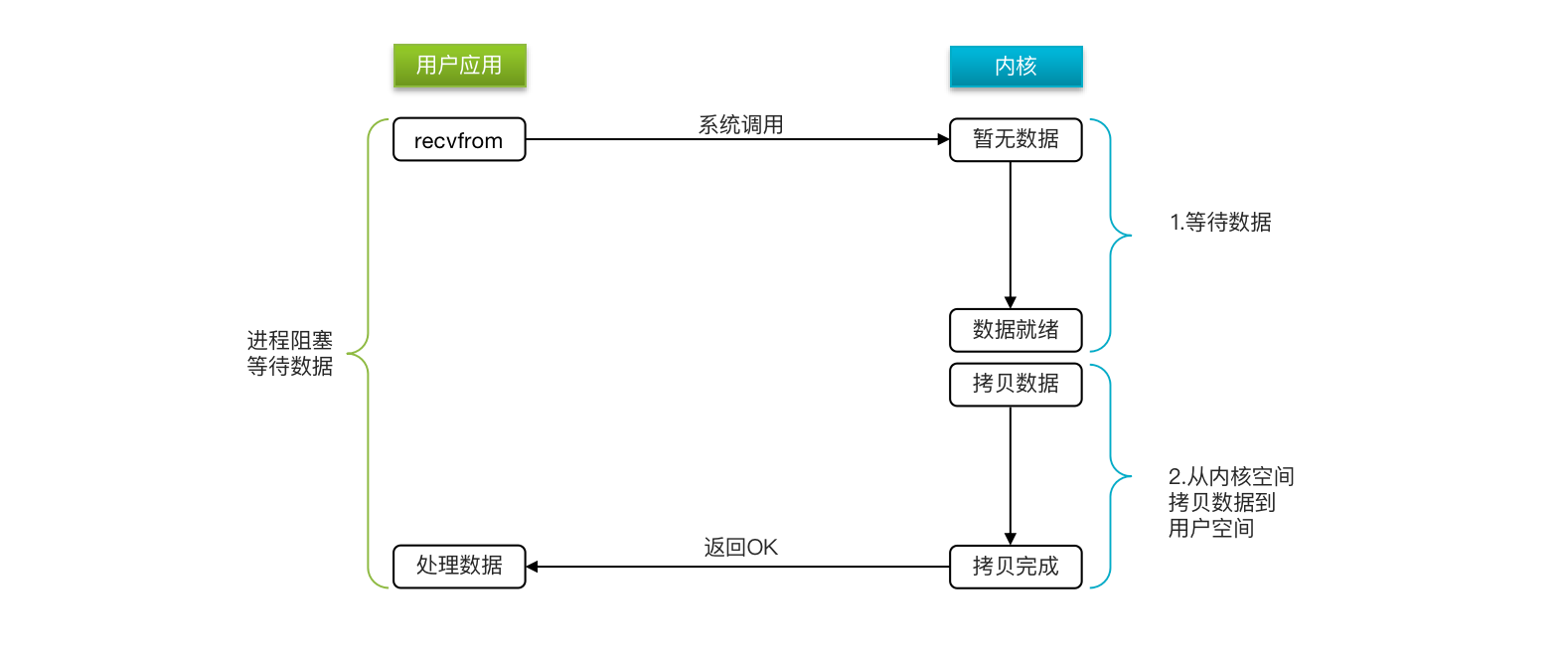
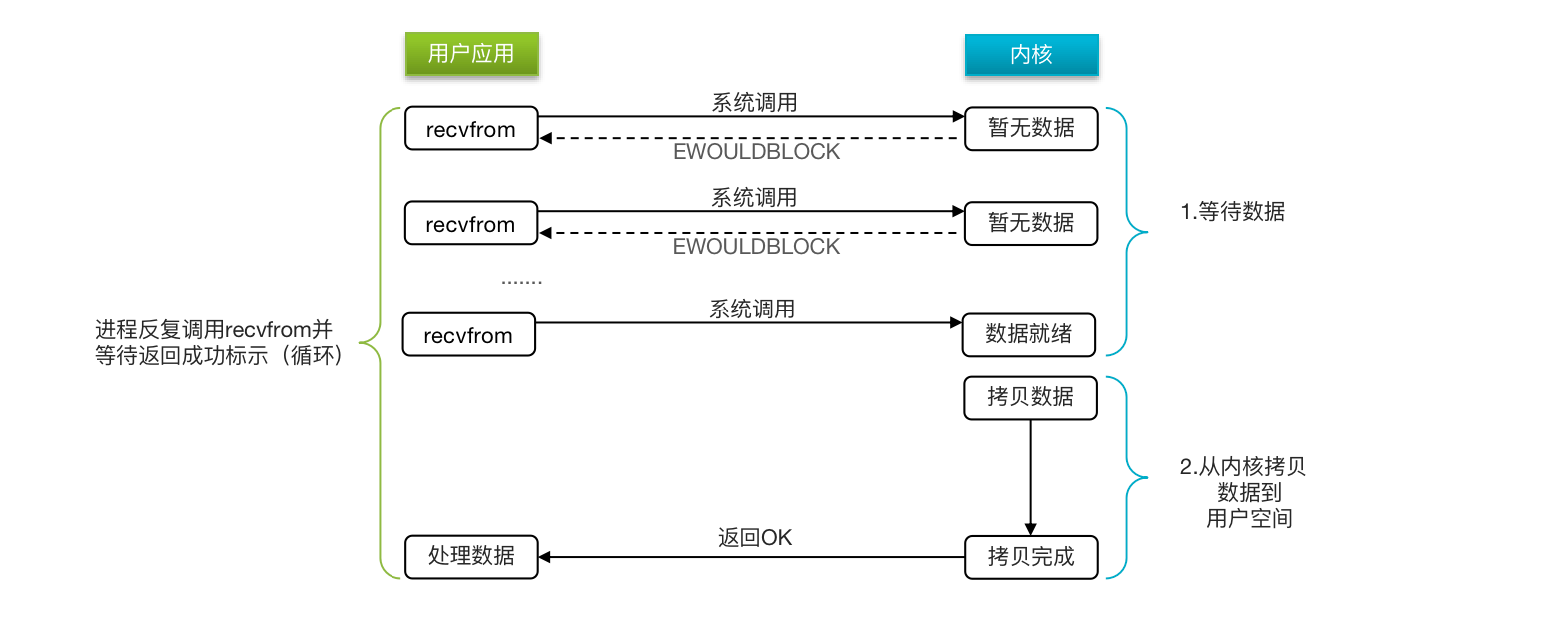
非阻塞IO
顾名思义,非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程。
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到error后,再次尝试读取
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
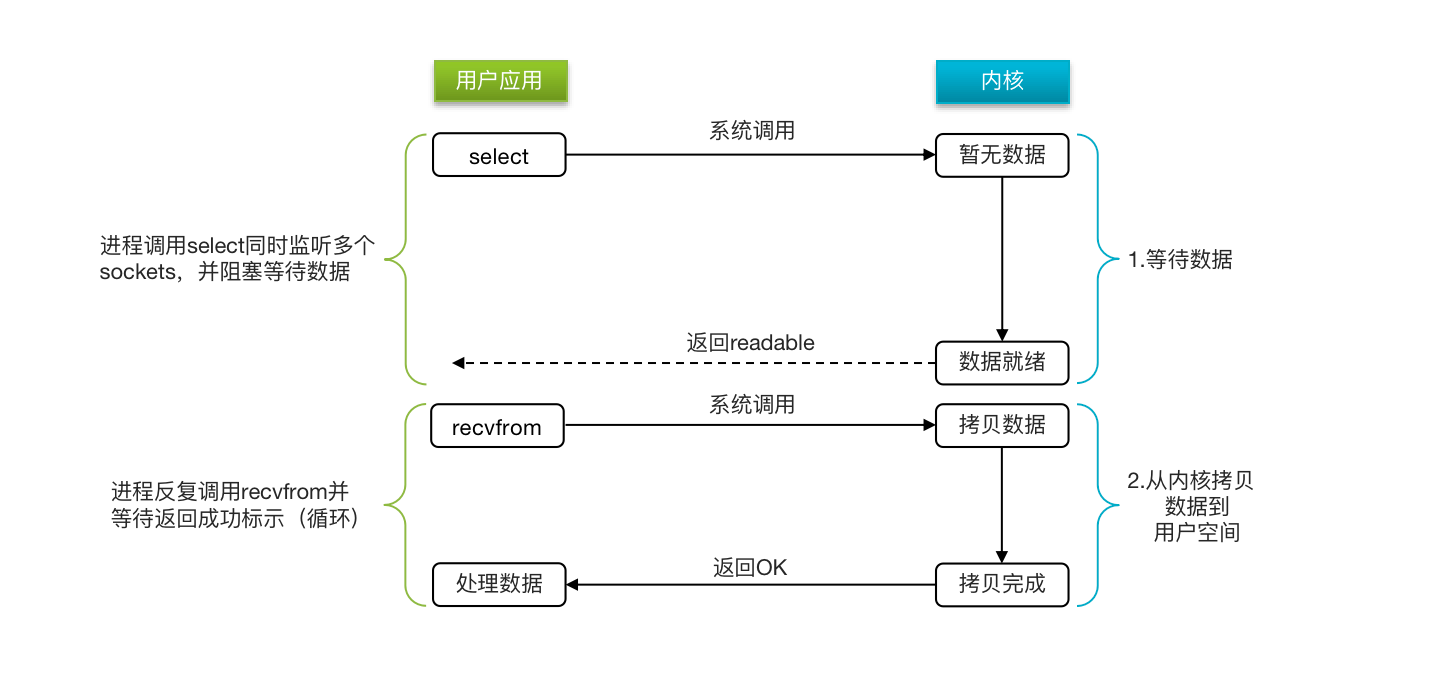
IO多路复用
利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
阶段一:
- 用户进程调用select,指定要监听的Socket集合
- 内核监听对应的多个socket
- 任意一个或多个socket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
IO多路复用是利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。不过监听Socket的方式、通知的方式又有多种实现,常见的有:
- select
- poll
- epoll
差异
- select和poll只会通知用户进程有Socket就绪,但不确定具体是哪个Socket ,需要用户进程逐个遍历Socket来确认。
- epoll则会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间。
网络模型
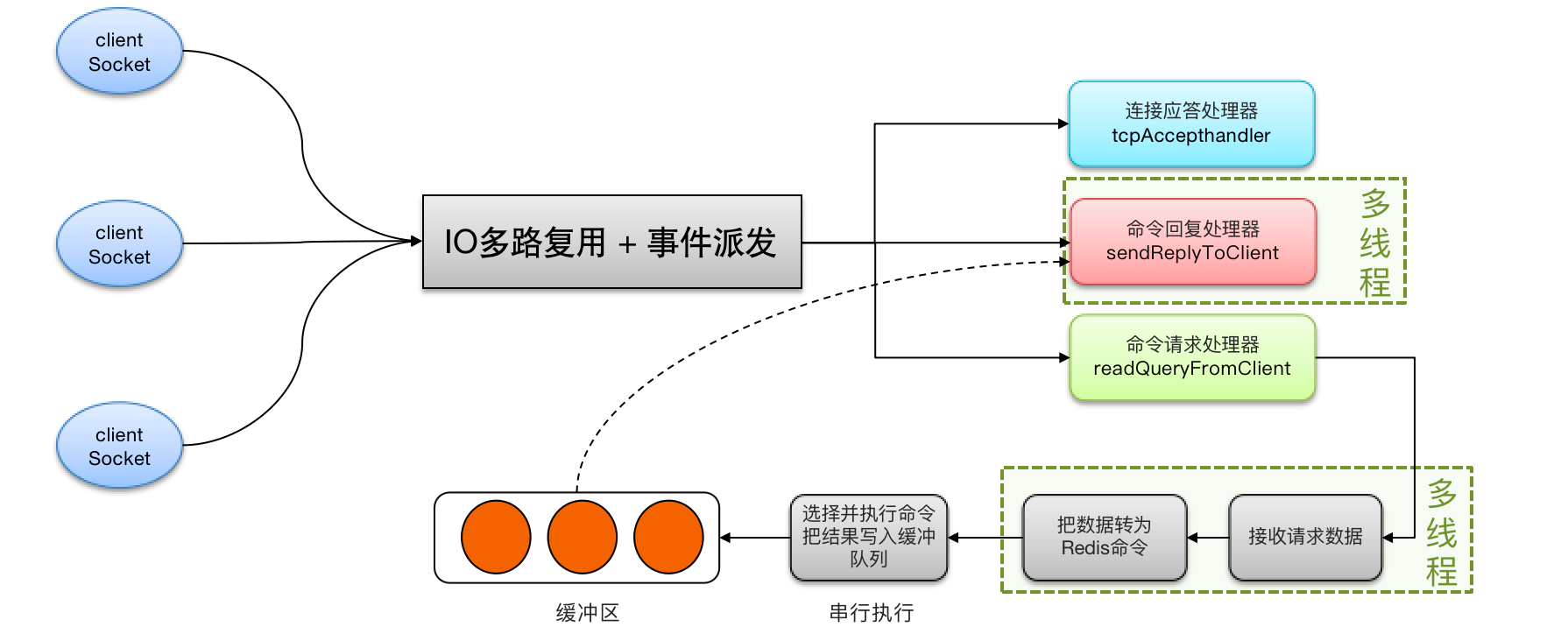
Redis通过IO多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装, 提供了统一的高性能事件库。
Redis在6.0之前是全部单线程的,在6.0之后对命令回复处理器和数据命令转化进行了多线程处理,执行命令还是单线程的。
💡思考:Redis 是单线程的,但是为什么还那么快?
- 完全基于内存的,C语言编写。
- 执行命令采用单线程,避免不必要的上下文切换可竞争条件。
- 使用多路 IO 复用模型,非阻塞IO;bgsave 和 bgrewriteaof 都是在后台执行操作,不影响主线程的正常使用,不会产生阻塞。
💡思考:为什么要使用 IO 多路复用
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度, I/O多路复用模型主要就是实现了高效的网络请求。
💡思考:能解释一下I/O多路复用模型?
IO 多路复用是指利用单个线程来同时监听多个 Socket ,并在某个 Socket 可读、可写时得到通知,从而避免无效的等待,充分利用 CPU 资源。目前的 IO 多路复用都是采用的 epoll 模式实现,它会在通知用户进程 Socket 就绪的同时,把已就绪的 Socket 写入用户空间,不需要挨个遍历 Socket 来判断是否就绪,提升了性能。
其中 Redis 的网络模型就是使用 IO 多路复用结合事件的处理器来应对多个 Socket 请求,比如提供了连接应答处理器、命令回复处理器,命令请求处理器;
在 Redis6.0 之后,为了提升更好的性能,在命令回复处理器使用了多线程来处理回复事件,在命令请求处理器中,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
缓存冷热数据分离
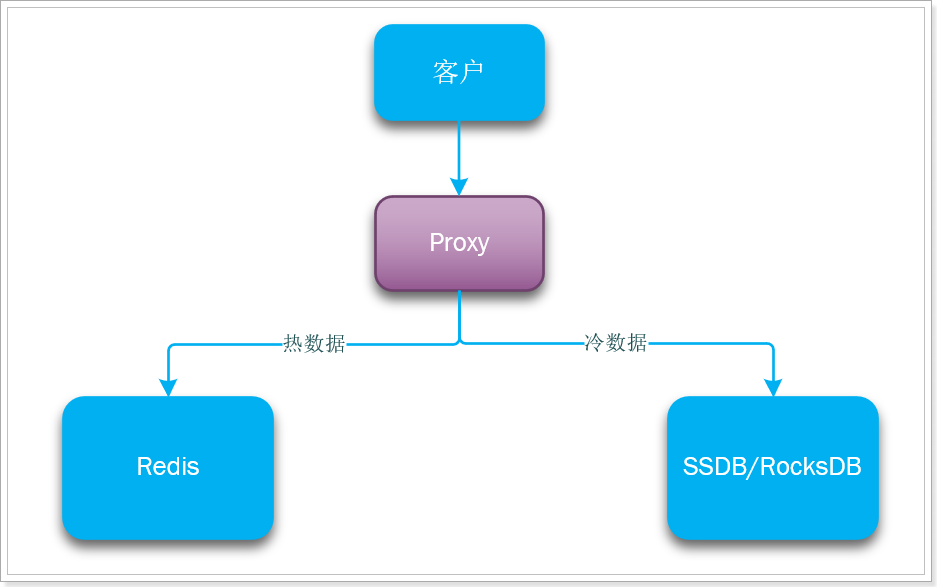
背景资料:
Redis使用的是内存存储,当需要海量数据存储时,成本非常高。
经过调研发现,当前主流DDR3内存和主流SATA SSD的单位成本价格差距大概在20倍左右,为了优化redis机器综合成本,我们考虑实现基于热度统计 的数据分级存储及数据在RAM/FLASH之间的动态交换,从而大幅度降低成本,达到性能与成本的高平衡。
基本思路:基于key访问次数(LFU)的热度统计算法识别出热点数据,并将热点数据保留在redis中,对于无访问/访问次数少的数据则转存到SSD上,如果SSD上的key再次变热,则重新将其加载到redis内存中。
目前流行的高性能磁盘存储,并且遵循Redis协议的方案包括:
- SSDB:http://ssdb.io/zh_cn/
- RocksDB:https://rocksdb.org.cn/
因此,我们就需要在应用程序与缓存服务之间引入代理,实现Redis和SSD之间的切换,如图:
这样的代理方案阿里云提供的就有。当然也有一些开源方案,例如:https://github.com/JingchengLi/swapdb